Introduction
阅读Speech and Language Processing这本书的一些笔记。
Words and Tokens
我们需要一个东西来建模语言,下面是我们的选择:
Words
为什么不用词?
- 有些语言没有orthographic words
- 词的数量会随着文章增长,词汇表永远都会覆盖不足
Morphemes
语素类型
- 屈折语素:inflectional morphemes
- 派生语素:derivational morphemes
- 附着语素:clitic
语言类型
- Analytic
- polysynthetic
- fusional
- agglutinative
为什么不用语素?
- 语素很复杂,很难定义
- 不同语言不同且难以统一
Unicode
Unicode的历史
- ASCII
- CJKV
- 不断更新中,越来越多,Unicode 16.0已经包含超过150000个字符
Code Points
- U+:表示接下来要用Unicode十六进制表示一个code point
- U+0061:0x0061一个意思,也就小写字母a。
UTF-8
目前最常用的encoding字符的方式。中文字符 “中” 的 Unicode 码点是U+4E2D,UTF-8 编码后为 3 个字节:0xE4 0xB8 0xAD
UTF-8是一种变长编码,兼容ASCII。
- 如「世」,UTF-8 编码是
0xE4 B8 96,其中E4的二进制为11100110H,开头的1110H表示这是一个3字节字符的第一个字节。
Subword Tokenization: Byte-Pair Encoding
上面的三个候选都不行,word和morpheme难以规范定义,character可以通过unicode来定义,但又对于作为tokens来说太小了。
为什么要tokenize输入?
- 将输入转换为一组确定的、固定的单元(Token),能让不同的算法和系统在一些简单问题上达成共识。例如困惑度的计算。
- 对可复现很重要
- 为了消除unknown words的问题
为了消除unknown words问题,现代tokenizers自动引入了token包含那些比words小的token,叫subword。
使用Tokenizer - OpenAI API中的GPT-4o & GPT-4o mini来分词下面这一大段话:
For example, if we had happened not to ever see the word lower, when it appears we could segment it successfully into low and er which we had already seen. In the worst case, a really unusual word (perhaps an acronym like GRPO) could be tokenized as a sequence of individual letters if necessary.
最终得到的是
 现在最流行的tokenization algorithm有两个:
现在最流行的tokenization algorithm有两个:
- Byte-Pair Encoding(BPE)
- Unigram Language modeling(ULM)
BPE
通过分析训练语料,自动学习出一套子词集合(词汇表),使得高频出现的字符 / 子词组合被合并为更大的子词单位。
训练方法介绍。
BPE encoder
BPE in practice
通常,我们会对 UTF-8 编码文本的单个字节执行 BPE 操作。BPE 处理 “中” 时,输入并非U+4E2D这个码点,而是E4、B8、AD这三个独立字节。
仅在预先切分出的单词内部执行 BPE 操作,有助于避免潜在问题。
一些英语里的小发现:
- 大多数单词的tokens是他们自己,包含词前空格。这样可以避免独立单词和单词内部的subword。
- 附着语素Clitics在名字后面分开单独成token,但在常见的词语后面会是token的一部分
- 数字通常三位一组
- 一些词,如Anyhow和anyhow会有不同的分割方法
这个和预处理有关系。
SuperBPE会合并常规的BPE子词分词,效率更高。
特别地,低资源语言的tokens更碎,就会输出边长,最终LLM的效率变低。
Rule-based tokenization
Penn Treebank Tokenization Standard):事实性规范。
- 分开附着语素
- 保留连字符连接的词
- 分开所有的标点符号
Sentence Segmentation
sentence tokenization可以和word tokenization联合处理。
Corpora
语料库和语言数量、使用者的特征都有关。
code switching:在一次持续的交流)中,说话者或作者交替使用两种或多种 “语码”的现象。
datasheet:存储一句话的特征,如时间、说话人性格、阶级…
Regular Expressions
正则表达式的具体实现。包含字符析取、计数、可选性、通配符、锚点和边界、替换和捕获组、前向断言等。
Simple Unix Tools for Word Tokenization
可以在Unix、Linux系统中使用正则表达式。如tr -sc 'A-Za-z' '\n' < sh.txt表示从 sh.txt 文件中提取所有英文字母,并将非字母字符替换为换行符,同时压缩连续的非字母字符为单个换行符。
Minimum Edit Distance
最小编辑距离:将一个字符串通过 “插入”“删除”“替换” 三种基本操作转换为另一个字符串所需的最少操作次数
The Minimum Edit Distance Algorithm
一个经典的动态规划问题。
字符对齐:通过回溯编辑距离矩阵中的 “最优路径”,反向推导出将一个字符串转换为另一个字符串的具体操作序列。也就是路径可视化。
Exercies
点击展开
2.1
Write regular expressions for the following languages.
- The set of all alphabetic strings.
- The set of all lowercase alphabetic strings ending in “b”.
- The set of all strings from the alphabet {a, b} such that each “a” is immediately preceded by and immediately followed by a “b”.
2.2
Write regular expressions for the following languages. By “word”, we mean an alphabetic string separated from other words by whitespace, relevant punctuation, line breaks, etc.
- The set of all strings with two consecutive repeated words (e.g., “Humbert Humbert” and “the the” but not “the bug” or “the big bug”).
- All strings that start at the beginning of the line with an integer and end at the end of the line with a word.
- All strings that have both the word “grotto” and the word “raven” in them (but not, e.g., words like “grottos” that merely contain “grotto”).
- Write a pattern that places the first word of an English sentence in a register. Deal with punctuation.
2.3
Implement an ELIZA-like program, using substitutions such as those described on page 27. You might want to choose a different domain than a Rogerian psychologist, although keep in mind that you would need a domain in which your program can legitimately engage in a lot of simple repetition.
2.4
Compute the edit distance (using insertion cost 1, deletion cost 1, substitution cost 1) of “leda” to “deal”. Show your work (using the edit distance grid).
2.5
Figure out whether “drive” is closer to “brief” or to “divers” and what the edit distance is to each. You may use any version of distance that you like.
2.6
Now implement a minimum edit distance algorithm and use your hand-computed results to check your code.
2.7
Augment the minimum edit distance algorithm to output an alignment; you will need to store pointers and add a stage to compute the backtrace.
N-gram Language Models
本章介绍最简单的语言模型:N元语法语言模型。
N-Grams
概率链式法则
How to estimate probabilities
马尔科夫假设:假设一个单词的出现概率只和前面的一个单词有关。那么n-gram即只和前面的$n-1$个单词有关。
最大似然估计:已知前一个词$w_{n−1}$时,当前词$w_n$的概率
终止符号(end-symbol):所有可能句子的概率总和为 1,否则是特定长度的所有句子概率之和为 1。
Dealing with scale in large n-gram models
Log probabilities
N元语法的计算现在甚至能达到无限元。
对N元语法模型进行修剪也是很重要的。
Evaluating Language Models: Training and Test Sets
内部评估和外部评估。
训练集、开发集和测试集。
Evaluating Language Models: Perplexity
Perplexity(PPL):困惑度越低,说明模型对文本的预测越准确(即模型越 “不困惑”)。
- 具体来说,是“联合概率倒数的几何平均值”。
- 在计算的时候常常会取对数来将求乘积变为求和,避免数值问题
Perplexity as Weighted Average Branching Factor
困惑度也可以理解为加权平均分支系数。其中,语言的 “分支系数”指的是 “任何一个词之后可能出现的下一个词的数量”。
Sampling sentences from a language model
“0-1 数轴 + 区间映射”来理解采样的基本原理。
Generalizing vs. overfitting the training set
对于莎士比亚文本和华尔街日报的文本,两者差异过大以至于不能分别作为训练集和测试集。
所以说要确保训练集和测试集的领域要相似。
Smoothing, Interpolation, and Backoff
zero probability n-grams有两个问题:
- 低估了词语序可能出现的可能性,导致最终的性能变差
- 困惑度无法计算,因为无法除以0
因此需要Smoothing或者discounting
Laplace Smoothing
其实也就是add one smoothing,就是对于所有的N元语法都加一。
对于语言模型来说,结果并不是很好。对文本分类有效。
Add-k Smoothing
也就是对所有的都加K。
对语言模型来说仍然效果一般。
Language Model Interpolation
n 元语法插值法:加权融合不同阶数 n 元语法的概率,避免高阶的n元语法零概率导致的预测失效。
加权的$\lambda$应该设置成多少呢?可以从预留集held-out corpus中学习。使用EM(期望最大化)算法来学习。
Stupid Backoff
回退模型:高阶n阶的模型无法使用的时候,回退到低阶模型。
Discount:要让回退模型(backoff model)输出合理的概率分布,我们必须对高阶 n 元语法的概率进行 “折扣处理”(discount),从而预留出部分概率余量(probability mass),供低阶 n 元语法使用。但在实际应用中,人们常使用一种更简单的 “无折扣回退算法”—— 即名为Stupid Backoff。
Advanced: Perplexity’s Relation to Entropy
熵:不确定性的度量方式。可以理解是编码某个决策或某条信息所需的最小平均比特数。越不确定,熵越大。
熵率:平均的不确定性。自然语言的熵率定义为 “无限长序列中,每个词的平均熵”,反映语言的长期不确定性。例如,英文的熵率约 1-2 比特 / 词,意味着平均每个词需要 1-2 比特来编码。
平稳性:序列概率不随着时间改变。自然语言不是,但是N元语法是平稳的。
遍历性:长序列中包含了所有的短序列。
Shannon-McMillan-Breiman theorem:如果语言满足某些正则条件(准确地说,是平稳且遍历的),序列长度趋近于无穷大时,“序列的平均对数概率的负值” ,即经验熵率会以概率1收敛敛到该过程的理论熵率。
交叉熵(Cross-Entropy):我们虽然不知道数据的真实概率分布p,但是可以用模型m来近似p。(即我们虽然不知道自然语言的真实情况,但是可以用N元语法来近似。)交叉熵越小,模型越接近真实分布。
困惑度:困惑度是熵的指数形式。比较直观。
Excercies
点击展开
3.1
Write out the equation for trigram probability estimation (modifying Eq. 3.11). Now write out all the non-zero trigram probabilities for the I am Sam corpus on page 40.
3.2
Calculate the probability of the sentence i want chinese food. Give two probabilities, one using Fig. 3.2 and the ‘useful probabilities’ just below it on page 42, and another using the add-1 smoothed table in Fig. 3.7. Assume the additional add-1 smoothed probabilities $P(i|<s>) = 0.19$ and $P(</s>|food) = 0.40$.
3.3
Which of the two probabilities you computed in the previous exercise is higher, unsmoothed or smoothed? Explain why.
3.4
We are given the following corpus, modified from the one in the chapter:
<s> I am Sam </s>
<s> Sam I am </s>
<s> I am Sam </s>
<s> I do not like green eggs and Sam </s>
Using a bigram language model with add-one smoothing, what is $P(Sam | am)$? Include $<s>$ and $</s>$ in your counts just like any other token.
3.5
Suppose we didn’t use the end-symbol $</s>$. Train an unsmoothed bigram grammar on the following training corpus without using the end-symbol $</s>$:
<s> a b
<s> b b
<s> b a
<s> a a
Demonstrate that your bigram model does not assign a single probability distribution across all sentence lengths by showing that the sum of the probability of the four possible 2 word sentences over the alphabet a,b is 1.0, and the sum of the probability of all possible 3 word sentences over the alphabet a,b is also 1.0.
3.6
Suppose we train a trigram language model with add-one smoothing on a given corpus. The corpus contains V word types. Express a formula for estimating $P(w3|w1,w2)$, where $w3$ is a word which follows the bigram$ (w1,w2)$, in terms of various n-gram counts and V. Use the notation $c(w1,w2,w3)$ to denote the number of times that trigram $(w1,w2,w3)$ occurs in the corpus, and so on for bigrams and unigrams.
3.7
We are given the following corpus, modified from the one in the chapter:
<s> I am Sam </s>
<s> Sam I am </s>
<s> I am Sam </s>
<s> I do not like green eggs and Sam </s>
If we use linear interpolation smoothing between a maximum-likelihood bigram model and a maximum-likelihood unigram model with $λ₁ = 1/2$ and $λ₂ = 1/2,$ what is $P(Sam|am)$? Include $<s>$ and $</s>$ in your counts just like any other token.
3.8
Write a program to compute unsmoothed unigrams and bigrams.
3.9
Run your n-gram program on two different small corpora of your choice (you might use email text or newsgroups). Now compare the statistics of the two corpora. What are the differences in the most common unigrams between the two? How about interesting differences in bigrams?
3.10
Add an option to your program to generate random sentences.
3.11
Add an option to your program to compute the perplexity of a test set.
3.12
You are given a training set of 100 numbers that consists of 91 zeros and 1 each of the other digits 1-9. Now we see the following test set: 0 0 0 0 0 3 0 0 0 0. What is the unigram perplexity?
Logistic Regression and Text Classification
经典任务:
- sentiment analysis
- spam detection
- language id
- authorship attribution
Machine Learning and Classification
- 人工规则很脆弱,数据一变化就无法使用
- LLM的弱点:幻觉、无法解释。
因此最常见的分类方法是有监督机器学习。
- 概率分类器:输出样本属于每个类别的概率而不是类别标签,保证在合并的系统里不过早地输出结果。
分类器的核心组件:
- A feature representation of the input
- A classificaition function that computes $\hat{y}$
- An objective funcion that we want to potimize for learning
- loss function
- An algorithm for optimizing the objective function
- stochastic gradient descent algorithm
The Sigmoid Function
二分类逻辑回归的目标是:计算样本属于正类的概率。
- 第一步:计算线性得分$z=w⋅x+b$,值域为$[-\infty, +\infty ]$
- 第二步:通过 Sigmoid 函数转换为概率: 将线性得分 z 映射到 $[0,1] $区间
$z$常常被称作Logit(对数几率)。Logit就是Sigmoid的反函数。可以提醒我们后续要加上Sigmoid进行转换,因为$z$并不是一个真实的值。
特别地,“正类的对数几率” 与特征呈线性关系。也就是当其他条件不变时,特征$x_1$每增加1,Logit就增加$w_1$。这非常有可解释性。
Classification with Logistic Regression
当概率大于0.5的时候,就把它分类到正类里。
Sentiment Classification
举了一个例子。
Other Classification Tasks and Features
Period disambiguation:确定句号是EOS还是其他。
Designing v.s. Learning features:
- 刚刚的例子,特征都是人工设计的。此外还有:
- feaure interactions:基础特征组合成的复杂特征
- feature templates:抽象的特征规范来定义特征。这里的特征空间是稀疏的,此外特征一般是字符串描述的Hash值。
- 人工设计太复杂了。因此现代的NLP系统都是用Representation Learning来解决。
standardize和normalize。
Processing many examples at once
如果有许多的值要计算,可以使用matrix arithmetic来一次计算完。
Multinomial Logistic Regression
多项逻辑回归也称softmax regression,老的教材上也叫maxent clasifier。
在多项逻辑回归中,直接输出结果而不是一个概率值。
- hard classification
Softmax
Sigmoid函数在多分类情况下的推广。
Applying Softmax in Logistic Regression
可以使用矩阵运算方式加快计算。
$$\hat{y}=softmax(Wx+b)$$Doumbouya et al., 2025是这么认为的:逻辑回归将矩阵的每一行 $w_k$视为第 $k$ 类的原型(prototype),由于两个向量的相似度越高,它们的点积(dot product)值就越大,因此点积可作为衡量向量相似度的函数。模型最终将输入分配给相似度最高的类别。
Features in Multinomial Logistic Regression
特征权重同时依赖于输入文本和输出类别。

Learning in Logistic Regression
逻辑回归是如何实现学习的?
- 使system output(classifier output)和gold output(correct output)越接近越好。两者之间的距离可以称作损失函数或者代价函数。下面介绍交叉熵。
- 需要一个算法来最小化损失函数。下面介绍随机梯度下降算法。
The Cross-entropy Loss Function
条件最大似然估计:在给定$x$下,选择参数$w$和$b$使得$y$的对数概率最大。
这里损失函数是负对数似然损失(negative log likelihood loss),通常也被称为交叉熵损失(cross-entropy loss)。
介绍了一下为什么最小化交叉熵损失可以使得真实分布和预测分布更加接近。
Gradient Descent
梯度下降算法的原理。介绍了梯度、学习率。
The Gradient for Logistic Regression
逻辑回归的梯度就是
$$\frac{\partial L_{\mathrm{CE}}(\hat{y},y)}{\partial w_{j}}=-(y-\hat{y})x_{j}$$也就是预测值$\hat{y}$和实际值$y$之间的差乘输入值$x_j$。
The Stochastic Gradient Descent Algorithm
随机梯度下降算法是一种在线算法,可以边接收数据边学习。
SGD每次用单个随机样本计算梯度。
Mini-batch Training
batch training和mini-batch training的区别。
- batch gradient:所有的随机样本计算梯度。
- mini-batch gradient:小批量梯度下降算法。每次选择一小批随机样本计算梯度。
Learning in Multinomial Logistic Regression
多项式逻辑回归其实和二项式逻辑回归差不多。
- 本质是使用独热标签+概率向量的形式进行计算。
- 核心是 “对正确类别的预测概率取负对数”,得到交叉熵损失,其越小则预测概率越高。
Evaluation: Precision, Recall, F-measure
- confusion matrix
- accuracy
- precision
- recall
- F-measure
- F1
- a weighted harmonic mean of precision and recall.
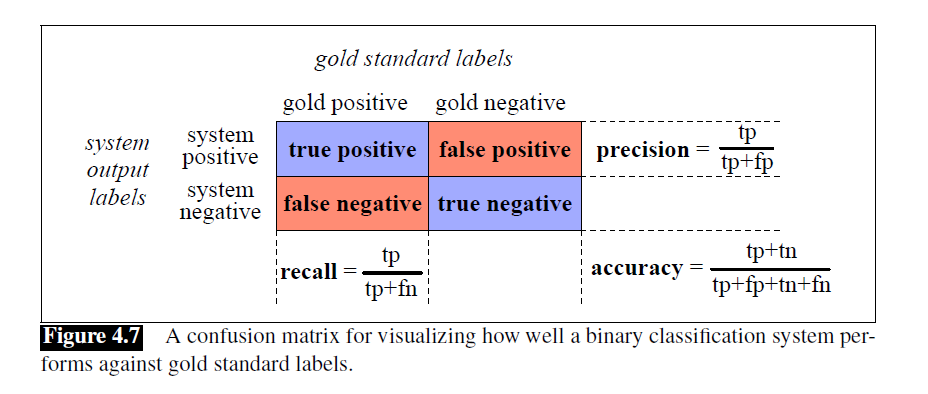
microaveraging v.s. macroaveraging
- 微观平均:更关注 “整体样本的预测准确性”,少数类错判代价低于多数类
- 宏观平均:更关注所有的类的错判代价的公平,少数类和多数类的代价相等

Test sets and Cross-validation
Cross-validation:解决测试集不足的问题。
- 固定训练集和测试集。
- 训练集中进行分割。
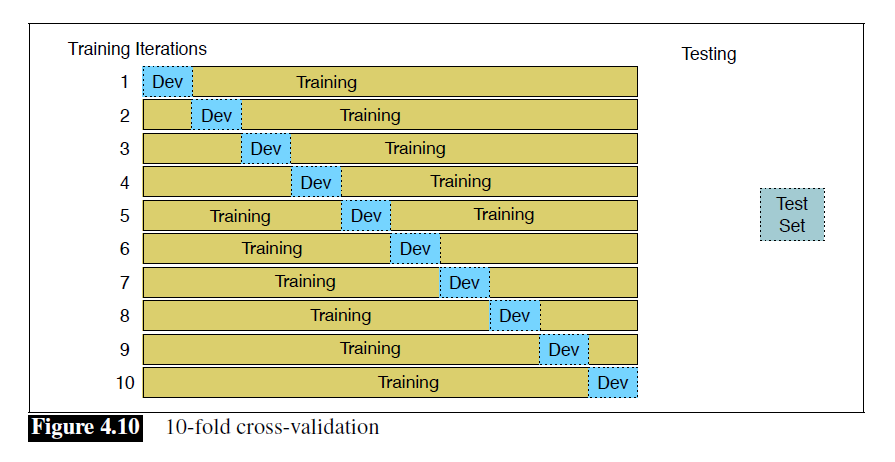
Statistical Significance Testing
统计显著性检验
- 不只是简单地检查A在测试集上的结果$M(A,x)$好于B在测试集上的结果$M(B,x)$。如果差很小的话,其实不一定能证明A的结果比B小,不具有统计学上的显著性。
- 设计一个效应量$\delta (x)=M(A,x)-M(B,x)$,原假设是$H_0 :\delta (x)\leq 0$。这样计算p值是否小于阈值可以得出是否显著性地A比B要好。
在NLP中,一般不用ANOVAs或者t检验,而是使用非参数检验:
- 近似随机化检验(Approximate Randomization Test)
- bootstrap 检验(Bootstrap Test)
方差分析和t检验都需要有假设:方差齐性或数据服从正态分布。所以只能用非参数检验。
The Paired Bootstrap Test
Bootstrap 检验的核心是 “重抽样”—— 从原始测试集x中有放回地随机抽取生成新的测试集。
 在新的测试集上,P 值等于 “重抽样测试集中,$d(x^{(i)})≥2d(x)$的数量占总重抽样次数b的比例”。判断此时的p值是否低于阈值就可以判断出是否是数据集本身的偏差导致了A比B要结果好。
在新的测试集上,P 值等于 “重抽样测试集中,$d(x^{(i)})≥2d(x)$的数量占总重抽样次数b的比例”。判断此时的p值是否低于阈值就可以判断出是否是数据集本身的偏差导致了A比B要结果好。
LLM的解释:Bootstrap 重抽样,就是在 “不改变天平初始倾斜(测试集偏向)” 的前提下,反复放 “随机重量(重抽样的样本)”,看左边会比右边多低多少格 —— 如果只是天平本身歪了,随机放重量时,左边最多低 2 格左右(常规波动);如果左边真的更重,就可能低 4 格以上(极端情况)。这种极端情况多了,超过了阈值,我们就更相信是天平本身的问题。
Avoiding Harms in Classification
representational harms:由于对特定社会群体的贬低或刻板印象导致的伤害。
toxic detection
model card
Interpereting Models
模型的可解释性也是很重要的。逻辑回归就是比较好的可解释的模型。
Advanced: Regularization
regularization来解决过拟合的问题,提高模型泛化能力。
- L2 regulaization
- L1 regulaization
- lasso
- ridge
Embeddings
分布假说:相似的上下文总会表现出相似的意思。
Embeddings分类
- static embeddings
- contextualized embeddings
学习embeddings和它的意义的理论称为向量语义。
- 自监督模型
- representation learning的一种
- 无需通过特征工程的人工制造representations
Lexical Semantics
- lemma:citation form,词元,引用形式,一个词的基本形式。
- wordform:词形,一个词的具体使用形态。
- word sense:词义。
- synonymy:同义关系。
- word similarity:词语相似度。
- SimLex-999中就让人们给一个词和另一个词的相似度打分。
- word relatedness/association:词汇关联性,所有能让词汇有关联感的关系。
- semantic fields
- topic models:特别地有Latent Dirichlet Allocation,LDA
- 最常见的关系
- hypernymy or IS-A
- antonymy
- mernoymy
- connotation
Vector Semantics: The Intuition
一个单词可以表示为多维语义空间中的一个点。而这个多维语义空间是从单词邻居的分布规律中推导而来的。
- tf-idf
- word2vec
- cosine
Simple Count-based Embeddings
- 词汇表一般在1-5万之间
- 稀疏向量表示:多数数值为0,目前有有效算法来有效存储和计算
- 权重函数
- 计数的时候可以用权重函数
- 目前最流行的方法是tf-idf
- 还有一些历史权重方式
Cosine for Measuring Similarity
使用余弦计算相似度。适用于稀疏长向量。
Word2vec
embeddings要区别于原来的稀疏长向量,通常指短而稠密的向量。
- 学习的权重变少,学习更快
- 有助于泛化和避免过拟合
- 能够更好捕捉同义性
skip-gram with negative sampling(SGNS)是word2vec两种方法的一种。word2vec是一种静态embedding方法,区别于动态embedding,如BERT表示。
这里有一个极具创新性的想法 ——不直接计算 “词与词的关联”(共现矩阵),而是通过一个 “预测任务” 让模型自动学习这种关联,再将学习成果(权重)作为词嵌入。
- 这被称为自监督方法
Skip-gram 模型的核心思路如下:
- 将目标词与其相邻的语境词视为正例。
- 从词汇表中随机选取其他词语,作为负例。
- 利用逻辑回归训练一个分类器,使其能够区分上述两种情况(即区分 “目标词与语境词是相邻关系” 和 “目标词与随机词无相邻关系”)。
- 将训练过程中学到的权重作为embedding。
The Classifier
Skip-gram目标是训练一个分类器,计算这个地方填这个词的概率。
- 核心思路:一个词是否可能出现在目标词附近,取决于它的嵌入向量与目标词的嵌入向量是否相似。
- 相似度计算:点积
- 点积结果并非概率值,还需要经过Sigmoid函数运算‘
Skip-gram模型其实是存储了每个单词的两个embeddings,一个作为目标词,一个作为上下文。分别从target matrix W和context matrix C矩阵中学习。
Learning Skip-gram Embeddings
positive examples:上下文滑动窗口
negative examples:词汇表中随机抽取,一般是positive examples的k倍,由目标词$w$和噪声词组成。
在抽样的时候,会设置一个权重系数$\alpha =0.75$来调整概率$P(w)$避免总是选择高频词。
学习目标:
- 最大化positive examples中学习的相似度
- 最小化negative examples中的相似度
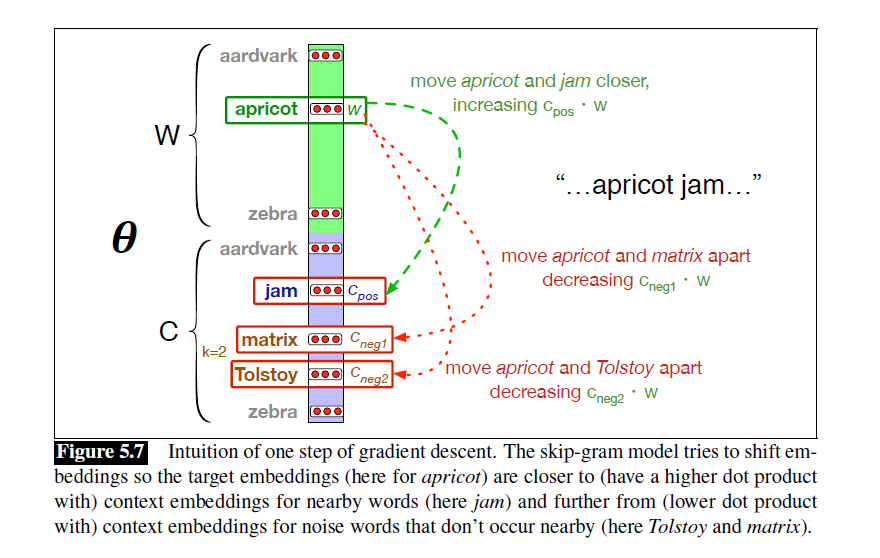 如图,目标是使得apricot和jam的点积更大,和matrix、Tolstoy的点积更小。
如图,目标是使得apricot和jam的点积更大,和matrix、Tolstoy的点积更小。
在学习完了之后,一般只使用W来表示。
Other kinds of static embeddings
fasttext
- 解决了word2vec的未知词问题
- subword models
GloVe
- Global Vectors
- 基于词词共现矩阵的概率
word2vec可以看成间接优化一个 “带PPMI(Positive Pointwise Mutual Information)权重的共现矩阵” 的函数。
我的一些想法:GNN是否也可以做类似的工作?GNN目前的方法就是直接处理图结构,进行局部图结构学习。不专门训练一个模型进行预测,而是把这个训练的模型的参数直接作为一个向量使用,反而能够更好地捕捉到隐含关系。
这种想法是否可以将LLM和GNN更好地连接起来?
Visualizing Embeddings
- 直接列出最相似的单词
- 聚类算法
- t-SNE:让低维空间中 “点与点的相似概率”,尽量和高维空间中 “点与点的相似概率” 一致
Semantic Properites of Embeddings
关联和相似的区别:越短的上下文得到的向量,相似越好找,关联越难;越长正好相反。
- 一阶共现:组合关系,一起组合出现,如write和poem
- 二阶共享:聚合关系,直接相关,如write和say
类比关系:平行四边形模型
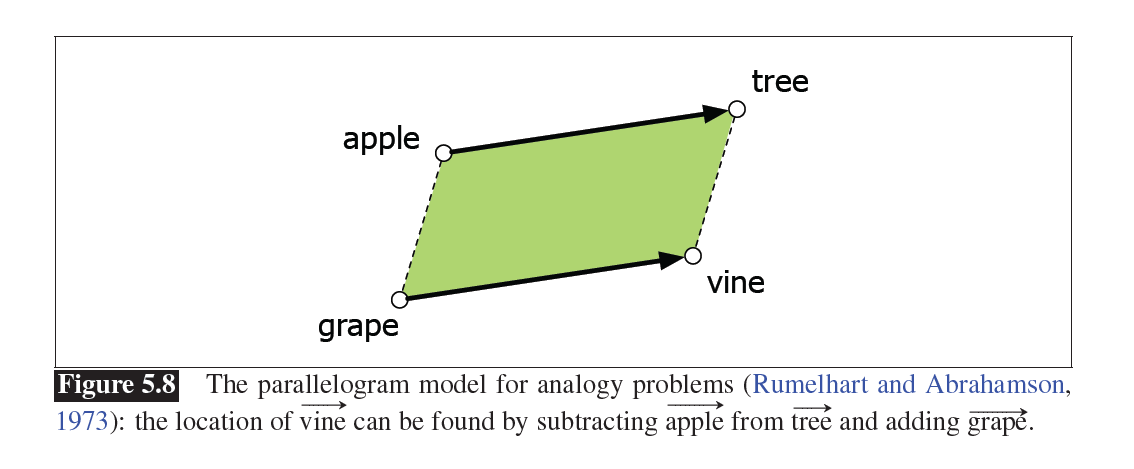 问题是只能用在明确的关系、短的距离和频繁的单词上。
问题是只能用在明确的关系、短的距离和频繁的单词上。
Embeddings and Historical Semantics
嵌入的应用。

很有意思。
- gay:愉悦的->明亮的->男同性恋
- broadcast:散播->报纸->BBC
- awful:庄严的->可怕的
Bias and Embeddings
allocational harm
embedding不仅反映输入,还放大偏见。
Evaluating Vector Models
相似度度量:
- 不含上下文
- WordSim-353
- SimLex-999
- TOEFL dataset
- 含上下文
- SCWS
- WiC
- semantic textual similarity task
类比度量:
- SemEval-2012 Task 2 dataset
所有的Embedding算法都会存在固有的变异性。建议使用bootstrap采样后的文档中训练多个embeddings并平均。
Neural Networks
McCulloch-Pitts neuron
feedforward
deep learning
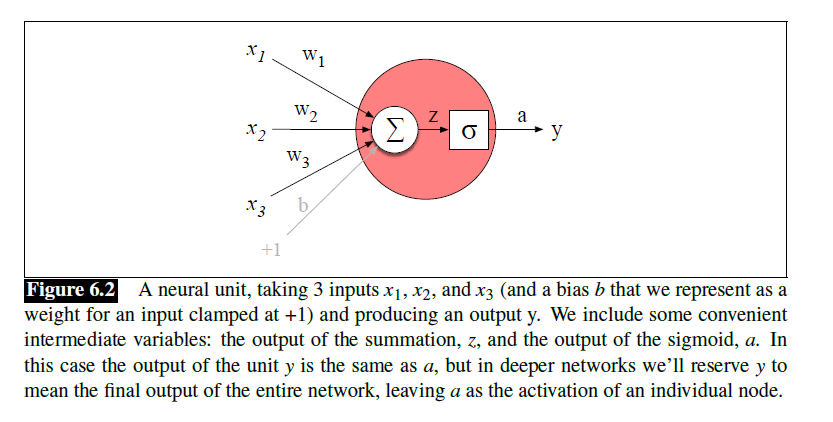
Units
bias term
activation:使用non-linear functions,如sigmoid、tanh、ReLU等
- sigmoid和tanh的问题:特别容易出现饱和的现象,如当特别靠近1的时候,此时的导数接近于0,输入的微小改变将无法引起输出的任何变化。这种现象称为梯度消失。
The XOR Problem
Minsky and Papert:一层神经元无法解决异或问题。如感知机。
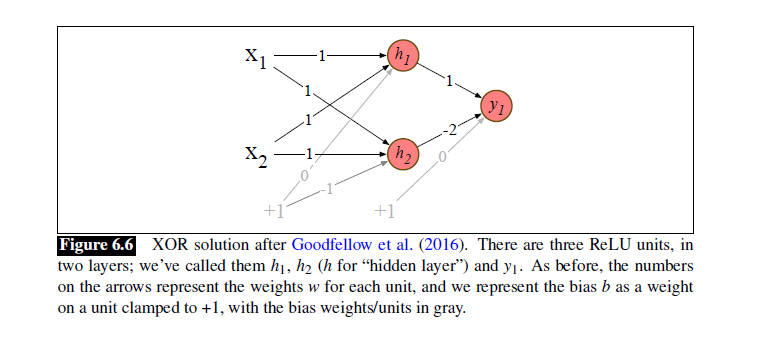
The Solution: Neural Networks
包含隐藏层的多层感知机MLP解决了这个问题。
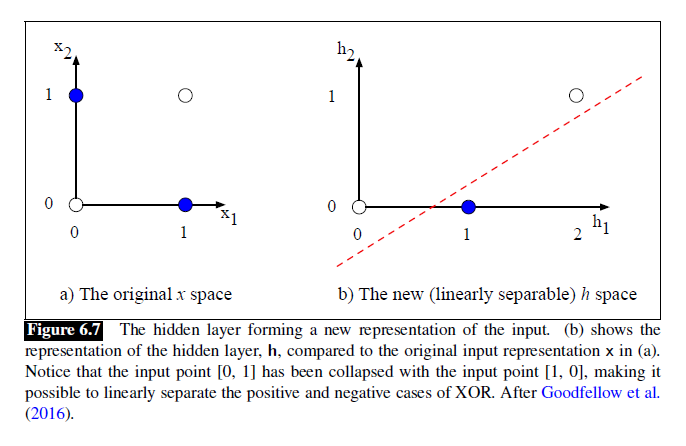
下面这个图,不管对于原来的[0,1]还是[1,0]都会将他们在隐含层里转化为[1,0]。而原来的[0,0]和[1,1]则变为[2,1],此时便线性可分。
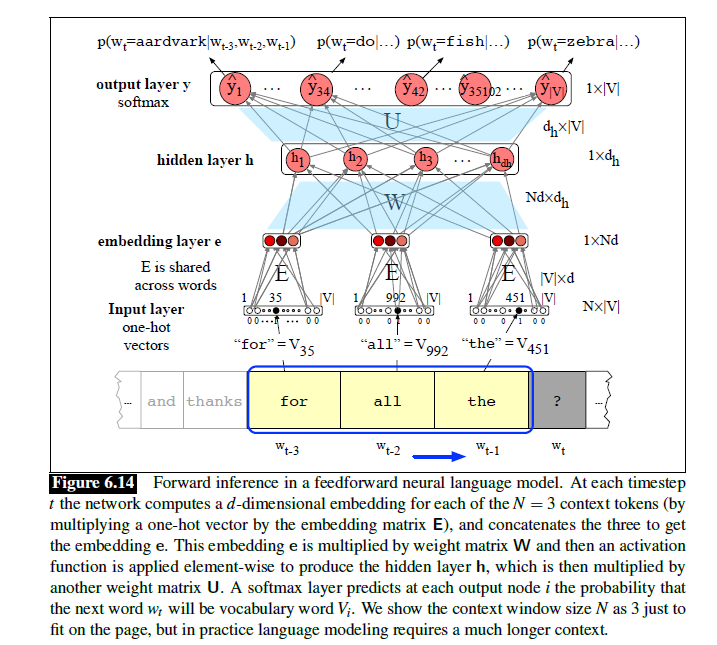
Feedforward Neural Networks
与RNN对应,前馈神经网络(FNN)不带有循环。
- 由于历史原因,FNN也称为多层感知机,MLPs,事实上现在的多层网络中已经不是感知机了。
- 感知机使用阶跃函数,现在的神经网络用的是多种非线性的单元如ReLUs或者Sigmoid等
前馈神经网络的标准结构是全连接的。
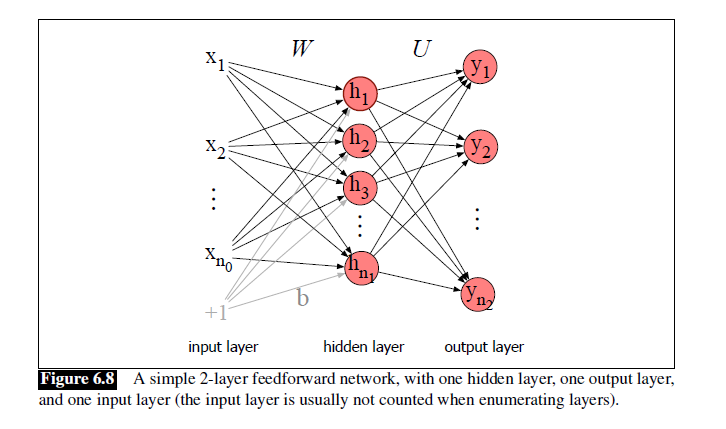 在这里,W作为输入层到隐含层的权重矩阵,U则是隐含层到输出层的权重矩阵。
在这里,W作为输入层到隐含层的权重矩阵,U则是隐含层到输出层的权重矩阵。
$$z=Uh$$
在得到输出结果$z$之后,由于$z$是一个实数值向量(其实就是logits),而分类需要的是概率分布向量,所以要对其进行归一化(normalizing)。这里使用的是softmax函数。
$$y = \text{softmax}(z)$$神经网络和多项逻辑回归的区别:
- 有许多层
- 中间层的激活函数不只使用sigmoid
- 特征可以不只是由人工的特征模板设计,而可以由网络自身得到
逻辑回归可以理解成一层的神经网络。
More Details on Feedforward Networks
为什么激活函数要非线性
替换偏置项:使用dummy node来代替原来的偏置项。也就是下图中把b换成一个新的固定为1的$x_0$。
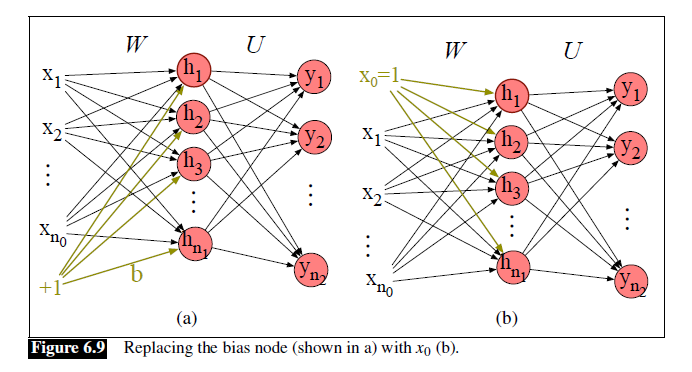
Feedforward Networks for NLP: Classification
嵌入矩阵、表示池化、表示学习先不讲,先学一下用前馈神经网络解决分类问题。
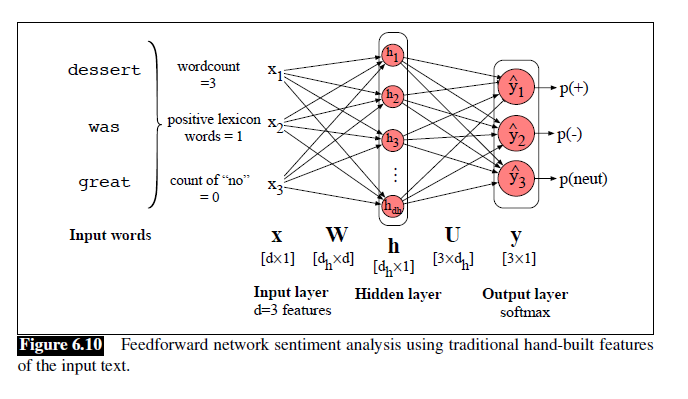
Neural Net Classifiers with Hand-built Features
人工设计的特征,除了把MLP换成FNN之外没变化。
Vectorizing for Parallelizing Inference
单个样本特征维度是d,有m个样本,就可以将输入写成一个矩阵X为m×d维。
其他的偏置项等也可以写成矩阵的形式,有助于最后的运算。此时有
$$H=\sigma(XW^T+\textbf{b})$$$$Z=HU^T$$$$\hat{Y}=\text{softmax}(Z)$$这里的X中行向量表示一个样本的完整特征。有的时候会写成$WX+b$,有的时候是$XW+b$。注意X的形状有所不同。
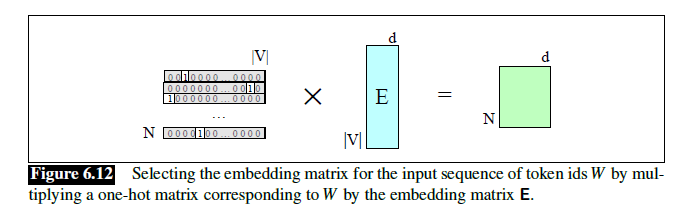
Embeddings as the Input to Neural Net Classifiers
static embeddings代替hand-designed features。
- 存储static embeddings的词典称为embedding matrix E
one-hot vector:从embedding matrix选取token embedding的方法
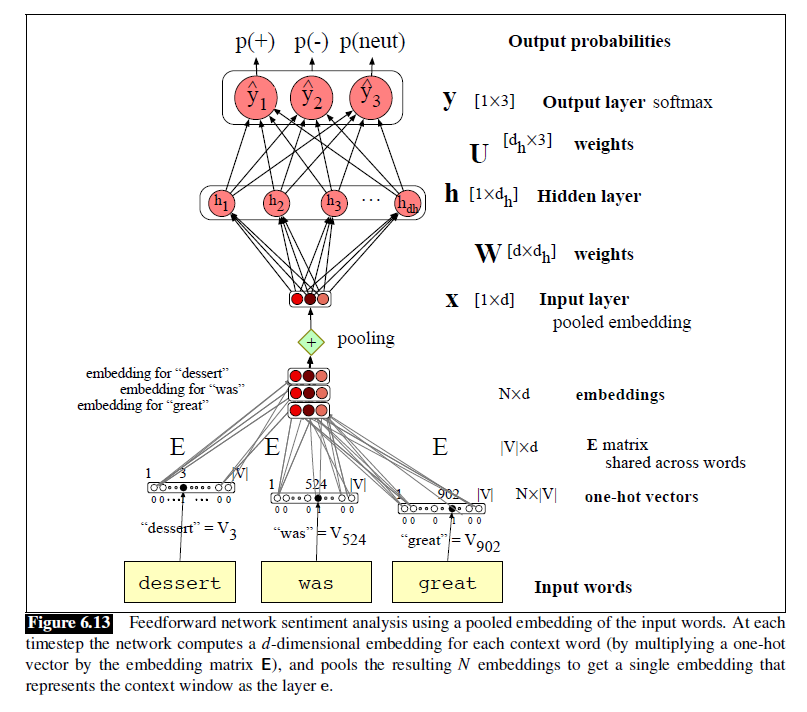
分类器:
- concatenation:适合对token顺序和细节敏感的任务,如语言建模
- pooling:适合对整体语义敏感的任务,如情感分析
- mean-pooling
- max-pooling
神经语言模型和N元语法模型的区别:
- 可以处理更多的上下文,更加泛化,预测更准确;速度更慢,训练更麻烦
- 使用embeddings表示词而不是word identity
Training Neural Nets
损失函数、交叉熵
误差反向传播/反向微分
Loss Function
交叉熵损失函数:负对数似然损失。用于输出为 “类别概率” 的任务。
Computing the Gradient
一层的时候可以用损失的导数,但是多层的时候需要用反向传播算法。
Computation Graphs
介绍了什么是计算图。
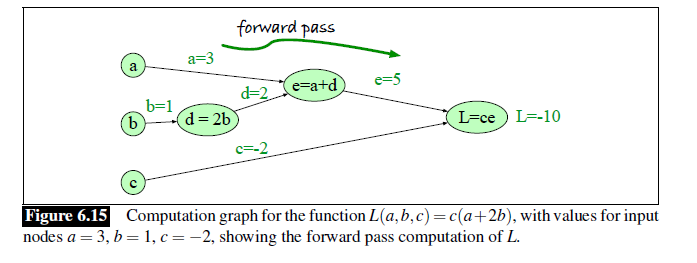
Backward Differentiation on Computation Graphs
反向传播:用链式法则一次性计算出所有参数的梯度。
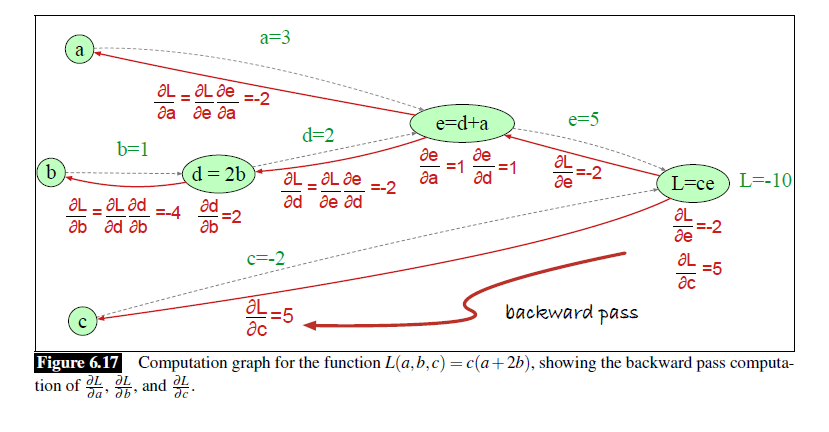 先正向传播一次,然后反向传播计算。
先正向传播一次,然后反向传播计算。
- 正向传播是为了得到损失值
- 反向传播是为了得到梯度,从而进行参数优化
当然在真正的神经网络中,计算会更加复杂。
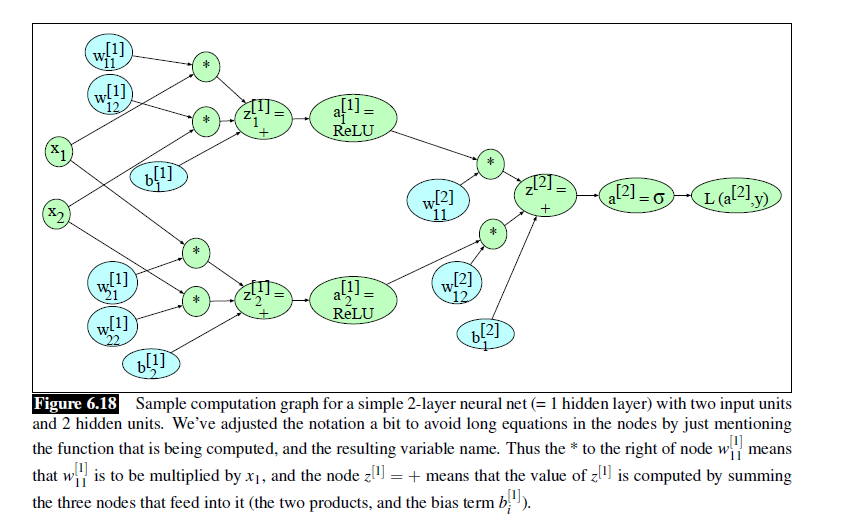 但是方法万变不离其宗。
但是方法万变不离其宗。
More Details on Learning
神经网络优化问题是一个非凸优化问题。目前有了很多好的正则化方法:
- 初始值不设为0,而是随机的一些小的数
- dropout
- 超参数:Adam等
GPUs等计算加速
Large Language Models
ELIZA
Distributional hypothesis
Pretraining
语言模型:依据前文预测下一个词的分布
发展:
- N元语法
- LSA/LSI,隐含语义分析,开始用向量表示词
- 神经网络语言模型neural language model
- RNN语言模型
- word2vec
- 预训练技术
- Transformer提出
- 掩码语言模型
- 自回归语言模型
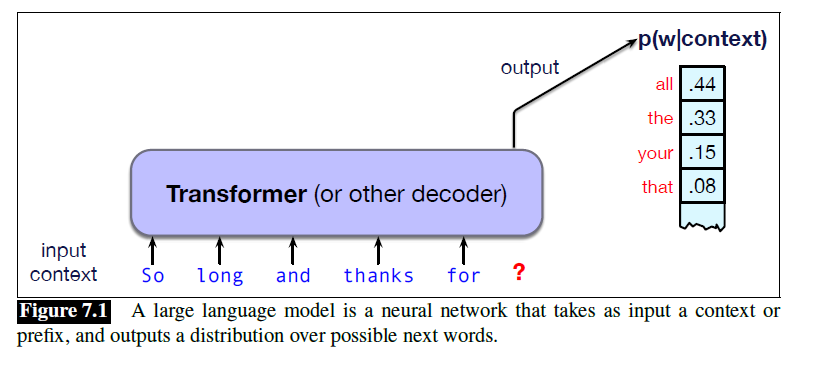
如果可以预测下一个词的概率分布,那么就可以从概率分布中进行采样,从而生成下一个词。这样就从预测模型变成了生成模型。
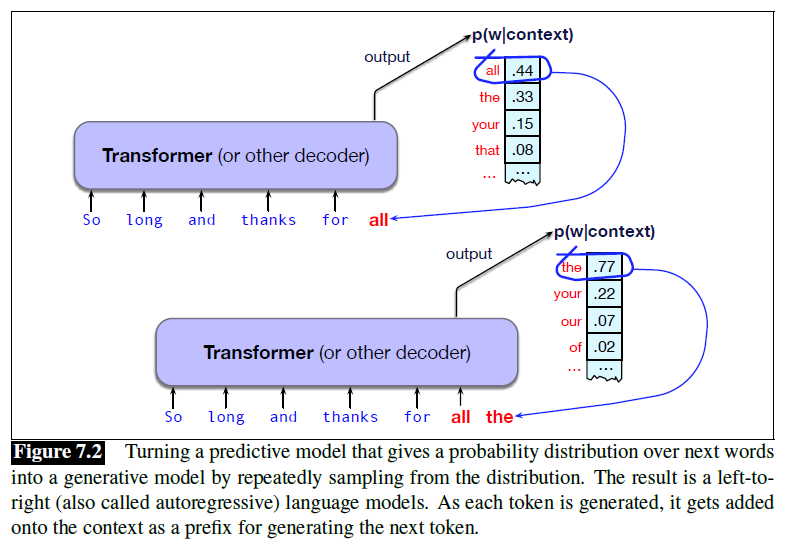
- 因果语言模型/自回归语言模型:从左到右依次生成
- 掩码语言模型:BERT等,可以同时利用左右两侧的信息
生成式AI
Three Architecture for Language Models
三种结构:
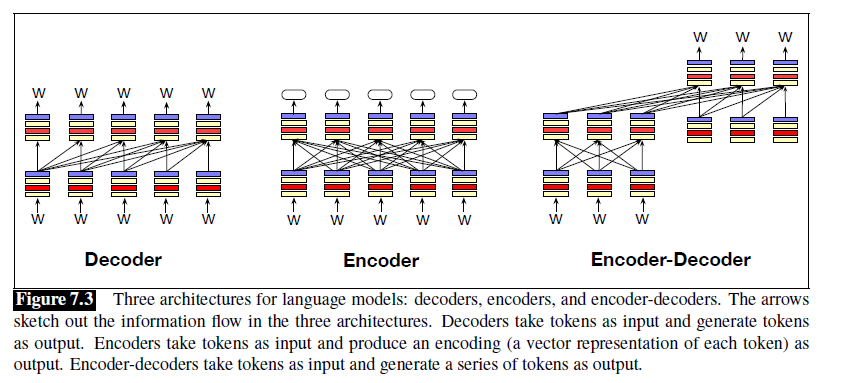
-
decoder:上文中的架构。输入为一系列的token,依次迭代生成输出的token。用于自回归语言模型。
- 生成文本等,如GPT
-
encoder:用于掩码语言模型。输入为文本,输出为标签。
- 分类文本等,如BERT
-
encoder-decoder:输入为一串token,输出也是一串token。
-
相比decoder来说,和输入输出token的关系更不紧密,这类模型用于在不同类型的标记之间进行映射
-
机器翻译等
-
他们都是基于神经网络构建的。
Conditional Generation of Text: The Intuition
不管什么任务,都可以简化为给定prompt的下一个词的预测任务。
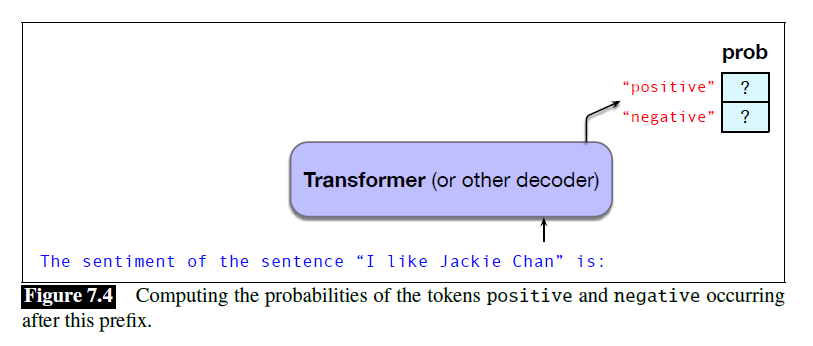
Prompting
指令微调
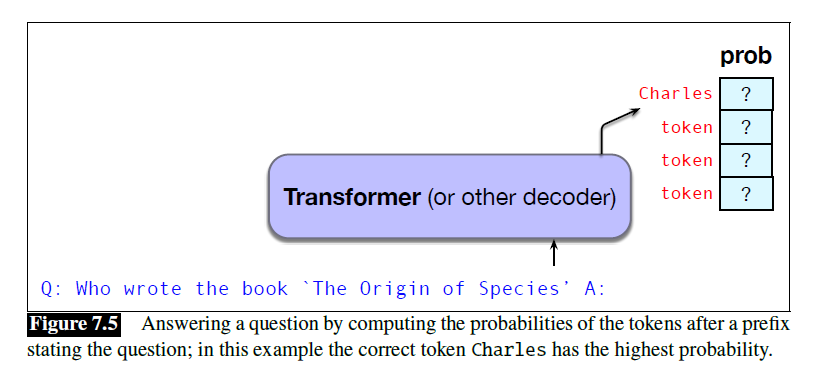
prompt
- Demonstrations
- Few-shot prompting
- Zero-shot prompting
这种Demonstrations可以手动筛选,也可以由优化器如DSPy来自动选择。此外,Demonstrations似乎并不是一定要给正确的问题和答案,错误的也行,主要作用是格式。
prompt:可以看做一个学习信号。提示词不会更新模型的权重,其改变的仅仅是模型的上下文信息以及网络中的激活状态。
- in-context learning:参数没有改变的学习
- System prompt:影响全局的一个文本prompt,被添加到所有用户prompt或查询的前面
Generation and Sampling
语言模型的内部网络会生成logits,再由softmax计算得到概率,随后在这些token中进行采样。
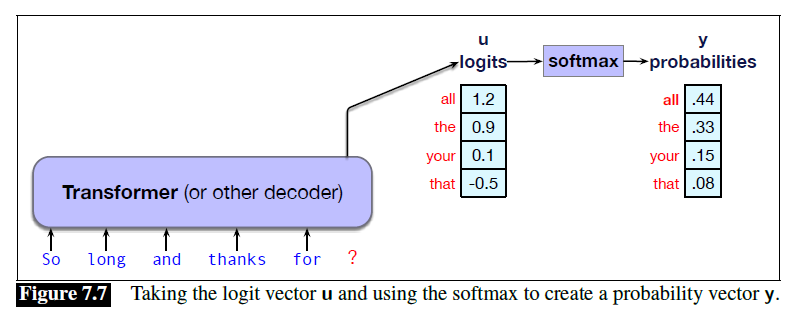
decoding:基于概率选择token生成的过程常称为decoding
自回归生成 D
Greedy decoding
贪心解码:选择概率最高的那个token生成(argmax)

效果不好——输入文本如果相同,结果是固定的。
束搜索
Random Sampling
按照分布采样,直到采样到EOS。
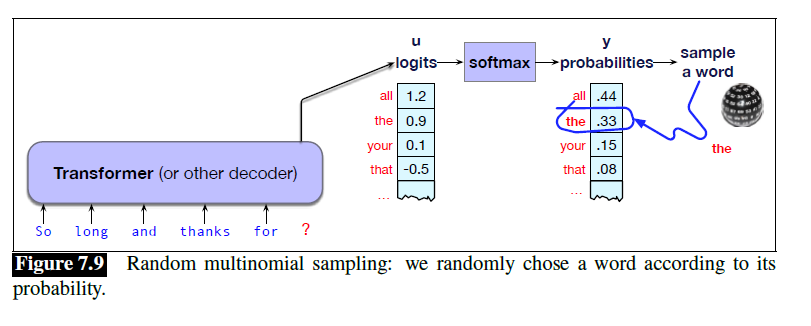
效果也不好——有些token虽然占比小,但是这些token很多,导致占比也不小。如果被采样到了,句子会变得很奇怪
Temperature Sampling
logits转化为probability的时候用带有temperature的softmax计算。

当$\tau \le 1$的时候,会倾向将高概率拉得更高,低概率拉得更低,反之则更容易选择到低概率事件。
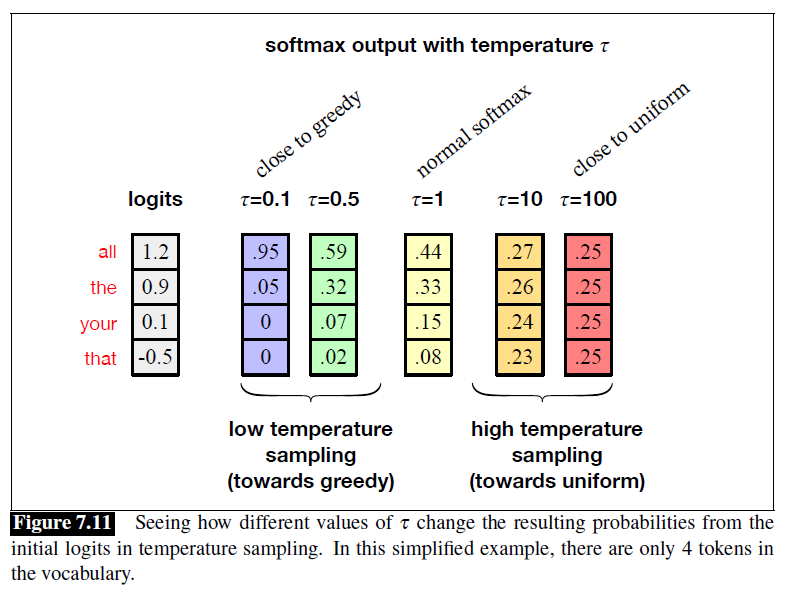
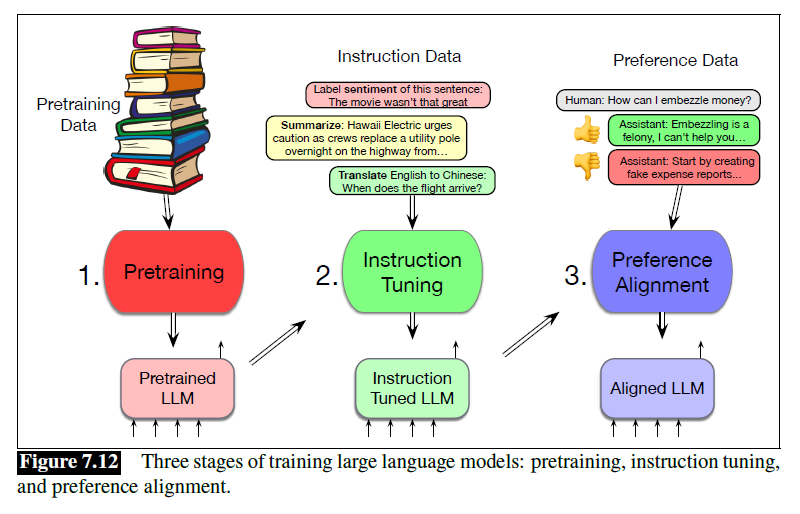
Training Large Language Models
一般分为三个阶段:
- 预训练
- 指令微调
- 偏好对齐
Self-supervised Training Algorithm for Pretraining
Teacher forcing:永远给模型正确的序列,而不是按照模型的预测接着往下来预测下一个词
如下图,网络中的权重会通过梯度下降进行调整,以最小化该批次上的平均交叉熵损失。
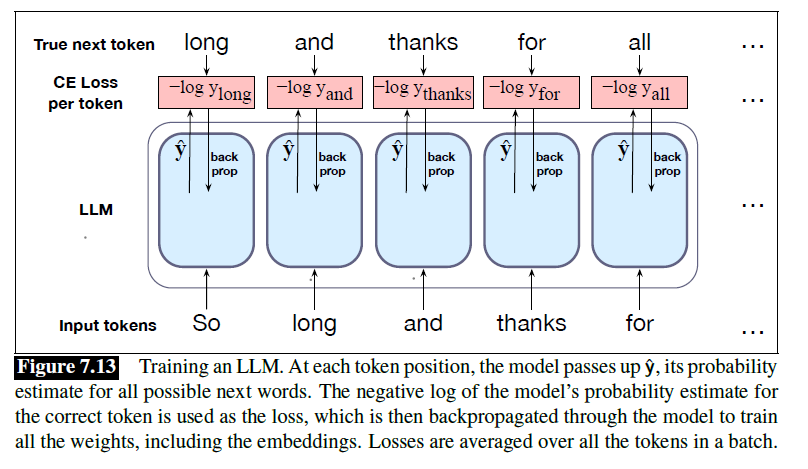
这些权重包括嵌入矩阵 E。由此学习到的嵌入,将能最有效地预测后续词语。
Pretraining Corpora for Large Language Models
训练数据可以用网络数据,并且加上一些精心筛选的数据。
- common crawl
- Colossal CLean Crawled Corpus
- The Pile
- Dolma
避免个人信息PII,去重,安全筛选,toxicity detection。注意版权、数据同意、隐私和偏差等问题。
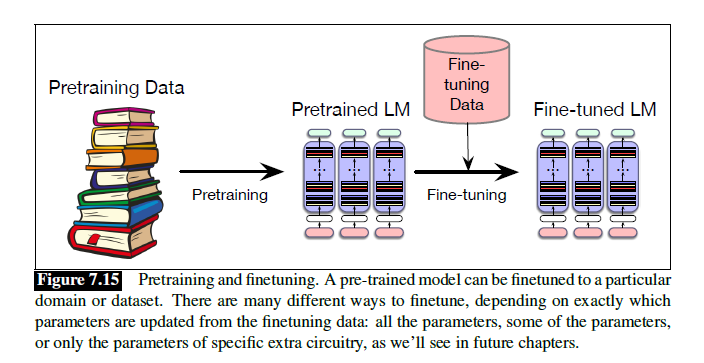
Finetuning
对已经与训练过的模型加入一些新的知识进行微调。如果新的数据是预训练的后面,也可以叫continued pretraining。
Evaluating Large Language Models
Perplexity
由于链式法则,使用对数似然来作为衡量语言模型性能的指标的话,测试集的概率大小会受到token数量的影响。文本越长,测试集的概率越小。
Perplexity:困惑度,长度归一化的指标。困惑度的具体公式是测试集概率的倒数,再按标记数量进行归一化。
$$\begin{aligned} \text{Perplexity}_{\boldsymbol{\theta}}(w_{1:n}) & =P_{\boldsymbol{\theta}}(w_{1:n})^{-\frac{1}{n}} \\ & =\sqrt[n]{\frac{1}{P_{\boldsymbol{\theta}}(w_{1:n})}} \end{aligned}$$困惑度越低,模型越好。
困惑度非常依赖tokens的数量,因此不能对两个使用不同tokenizer的模型进行比较,而是只能对使用同一个tokenizer的模型比较。
Downstream Tasks: Reasoniong and World Knowledge
准确率:可以直接使用下游任务来衡量。
- MMLU


但是问题是数据泄露。
Other Factors for Evaluating Language Models
模型大小,训练时间,推理时间,GPU数量
公平
leaderboards
Ethical and Safety Issues with Language Models
大模型幻觉问题:RAG
安全问题:安全微调和对齐
representational harms
隐私问题
情感依赖
增长谎言、宣传、虚假信息等文本生成