开发一种新药平均需要十年和十亿美元。Drug repurposing(药物重定位)走了一条捷径:已知安全性的老药,找新用途。阿司匹林从止痛药变成了心血管预防药,沙利度胺从镇静剂变成了多发性骨髓瘤治疗药。
但这条"捷径"本身也不容易——药物有成千上万种,疾病同样,候选组合是天文数字。计算方法的核心工作,就是从这个巨大的空间里找出有意义的配对。
LLM 的加入改变了什么?根据近期工作来看,大概有三条路线:① 把 LLM 的语义理解能力转化为 GNN 的节点特征;② 用 LLM 清洗训练数据而不是改模型;③ 让 LLM 直接做多源推理。
数据集背景
这个领域有几个被反复引用的基准数据集,先统一列出,避免后面重复解释:
| 数据集 | 药物数 | 疾病数 | 已知关联数 | 正样本率 |
|---|---|---|---|---|
| B-dataset | 269 | 598 | 18,416 | 11.45% |
| C-dataset | 663 | 409 | 2,532 | 1.57% |
| F-dataset | 593 | 313 | 1,933 | 1.05% |
| R-dataset | 894 | 454 | 2,704 | 0.67% |
正样本率的差异很关键:B-dataset 的 11% 相对好学,R-dataset 0.67% 意味着极端不平衡,大量未知关联中混杂着真正的负例。评估主要看 AUC、AUPR、F1,其中 AUPR 对不平衡数据更敏感。
- B-dataset:来自 SCMFDD,适用于常规场景
- C-dataset:来自 Bi-Random walk,由 Dndataset 和 F-dataset 整合,结合 ATC 编码和 DO 术语
- F-dataset:来自 PREDICT,侧重文本知识分析能力
- R-dataset:LLM-DDA 论文自建,整合 C/F-dataset 和 KEGG,用于极端稀疏场景
路线一:LLM 作为语义特征编码器
这条路线的逻辑是:结构化数据库(DrugBank、OMIM 等)能告诉你药物的靶点、结构,但捕捉不到文献中隐含的知识——一篇论文里可能早就暗示了某个药物对某类疾病有效,但这种关联从未被整理进数据库。用 LLM/BERT 读这些文本,把语义信息转成向量,再注入 GNN,就能补上这个盲区。
LLM-DDA
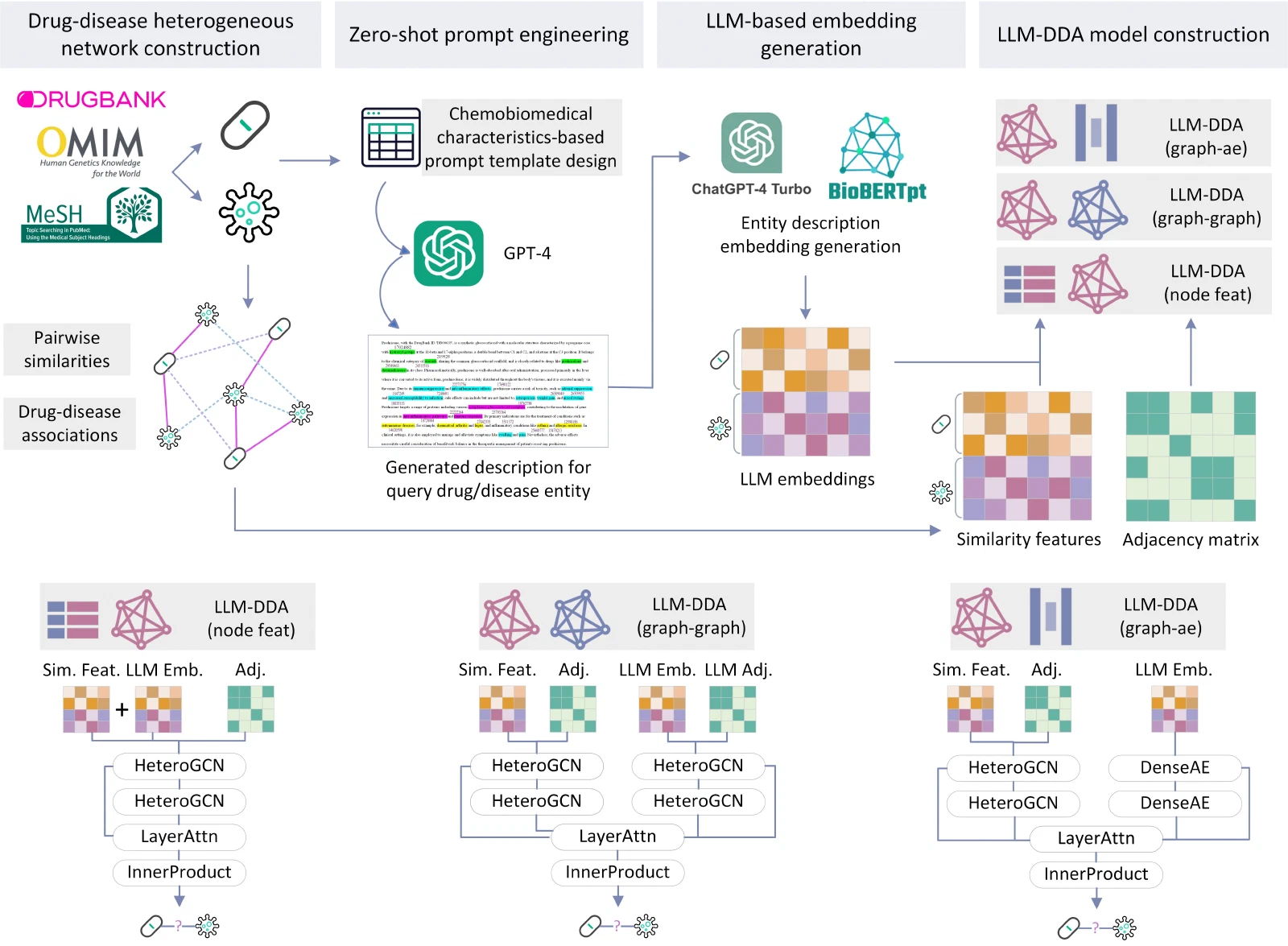
四步走:
- 异质网络构建:整合 DrugBank、OMIM、MeSH 等数据库,计算药物-药物、疾病-疾病的成对相似度,构建包含多种边类型的异质图
- 零样本提示工程:设计基于化学生物特征的 prompt 模板,用 GPT-4 为每种药物/疾病生成详细描述,挖掘数据库之外的潜在知识
- LLM 嵌入生成:用 ChatGPT-4 Turbo 和 BioBERTpt 对 GPT-4 生成的文本编码,输出语义向量
- 三种融合策略:
- node feat:LLM 嵌入直接作为 GNN 节点特征,最轻量
- graph-graph:双图并行,LLM 嵌入图和原始异质图各跑一路再融合
- graph-ae:结合图自编码器,更深度地融合语义和拓扑
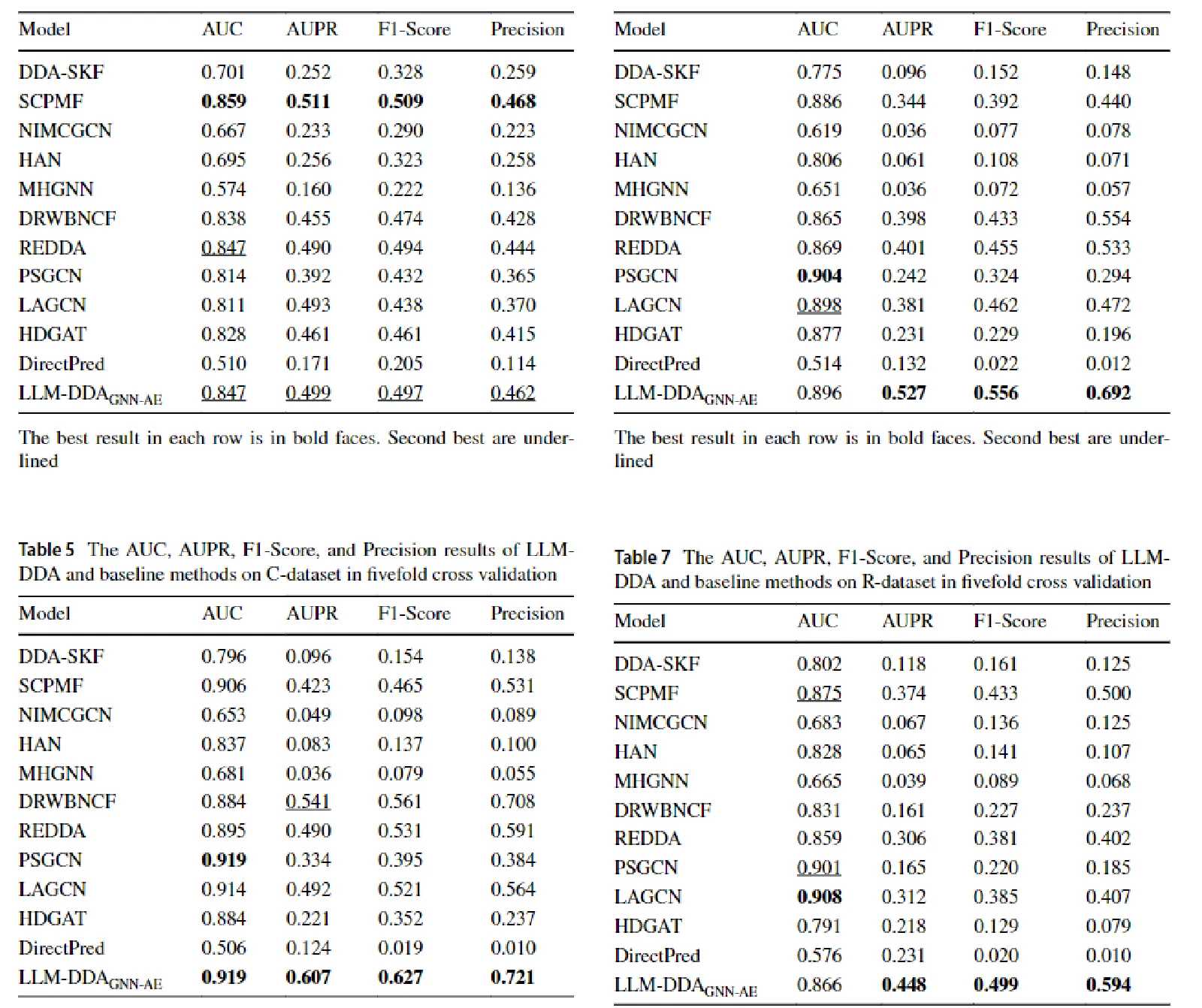
在四个数据集上,LLM-DDA 均优于纯 GNN 基线(REDDA、LAGCN、HDGAT)和 LLM 直接预测(DirectPred)。
LBMFF
Drug–disease association prediction with literature based multi-feature fusion
和 LLM-DDA 思路类似,但 LLM 部分换成了专门在生物医学文献上预训练+微调的 BERT。
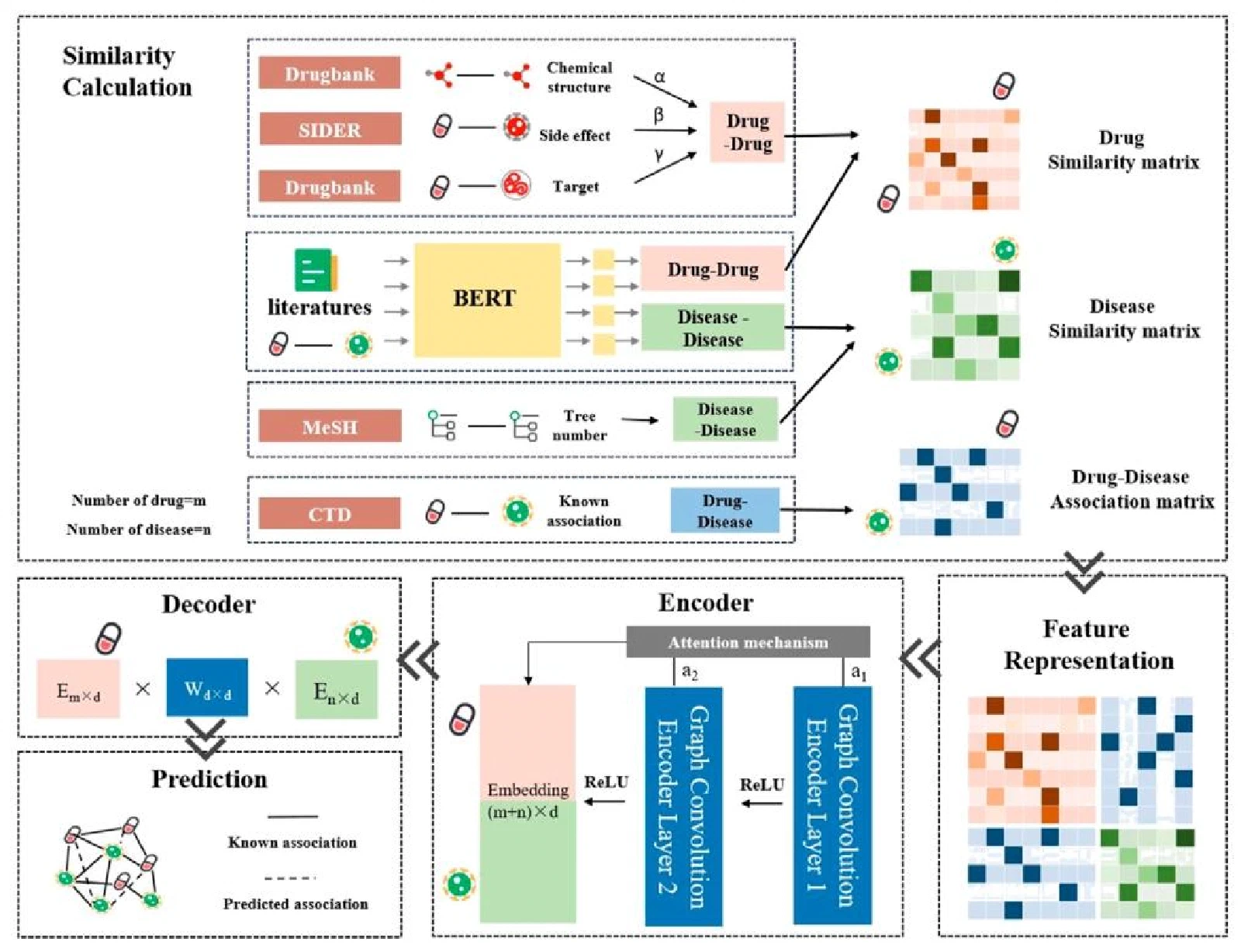
BERT 的使用方式:
- 预训练阶段:从 PubMed 筛选 673,665 篇相关文献,以"药物A[SEP]疾病B"格式训练 Masked LM 和 NSP 任务
- 微调阶段:用 CTD 数据库的已知关联对做正例、无关联为负例,微调后输出包含语义关联信息的向量
这个语义向量和来自 Drugbank(化学结构、靶点、副作用)、MeSH(疾病分类)的结构化特征拼接,一起送进带注意力机制的 GCN。解码器用简单的矩阵乘法还原药物-疾病关联得分。
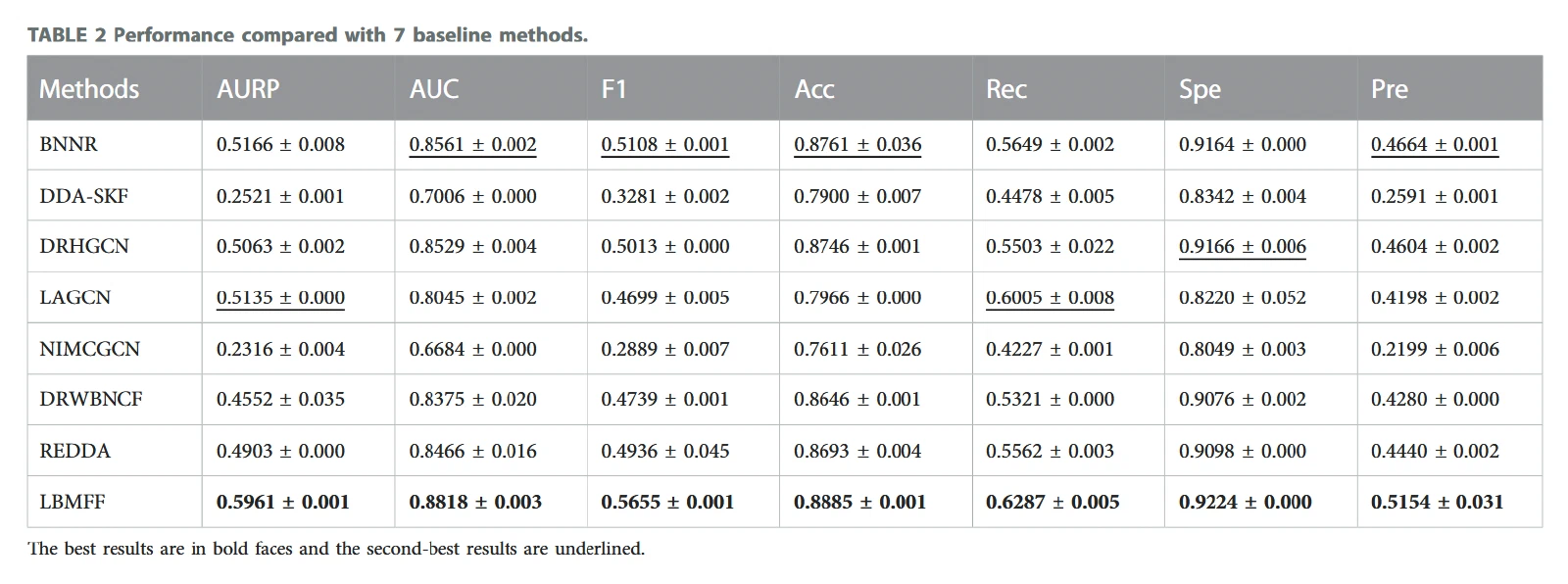
在 Zhang(B-dataset)和 TL-HGBI 两个数据集上,LBMFF 优于 DRHGCN、LAGCN、BNNR、NIMCGCN 等同期 SOTA。
路线二:LLM 改造数据,而不是改模型
Improving drug repositioning with negative data labeling using large language models
这篇思路最巧。
背景痛点:药物重定位的监督模型缺乏可靠的阴性数据。药物在临床试验中失败,不代表它对这种疾病无效——终止原因可能是资金不足、样本量不够、适应症选错。直接把"未被验证有效"当负例,引入的噪声比想象的大。
传统 PU Learning 要么把所有未标注数据当负例(class imbalance 爆炸),要么随机下采样(丢掉真实信息)。
方案:让 GPT-4 读临床试验记录,判断"这个试验的失败是否真的说明药物对该疾病无效"。从 AACT 数据库的 2539 个前列腺癌试验里,排除结果未公布和非疗效原因终止后,剩余 1442 个由 GPT-4 分析,最终识别出 26 个真阳性和 54 个高质量真阴性。
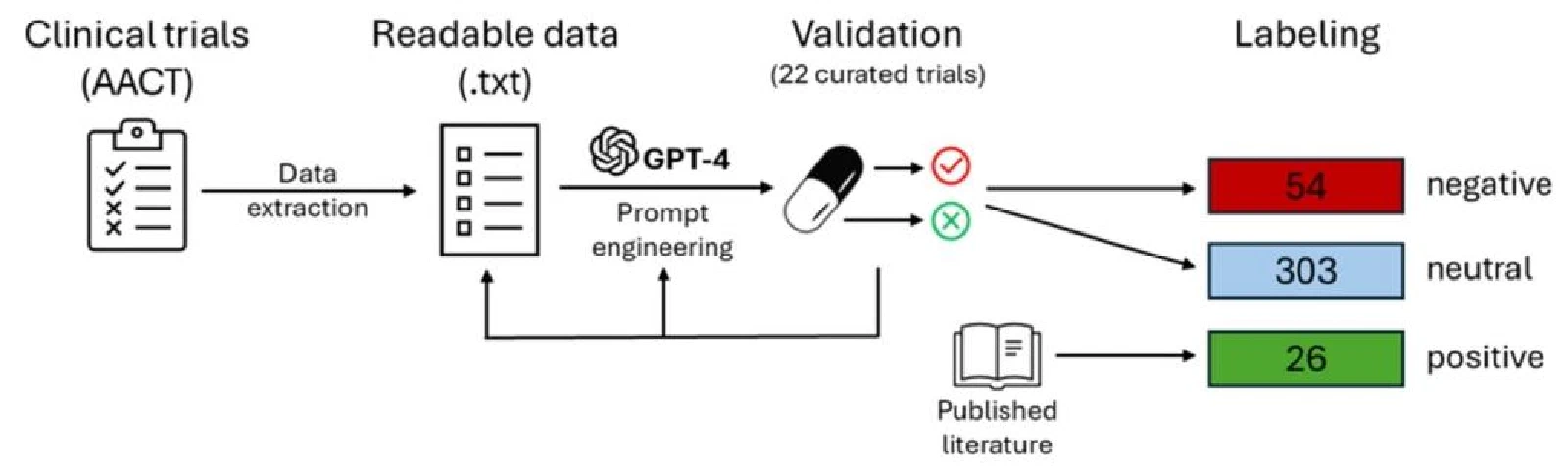
特征构建:
- Knowledge-based 特征:DrugBank 的药物-基因、药物-靶点、药物-通路关系,独热编码
- Network-based 特征:药物-药物相似性、PPI、Gene Ontology 的多层生物网络拓扑特征
结果:用 GPT-4 标注数据训练的模型(LogL1、RF、SVM),在 MCC 上显著高于 PU Learning 两种变体。
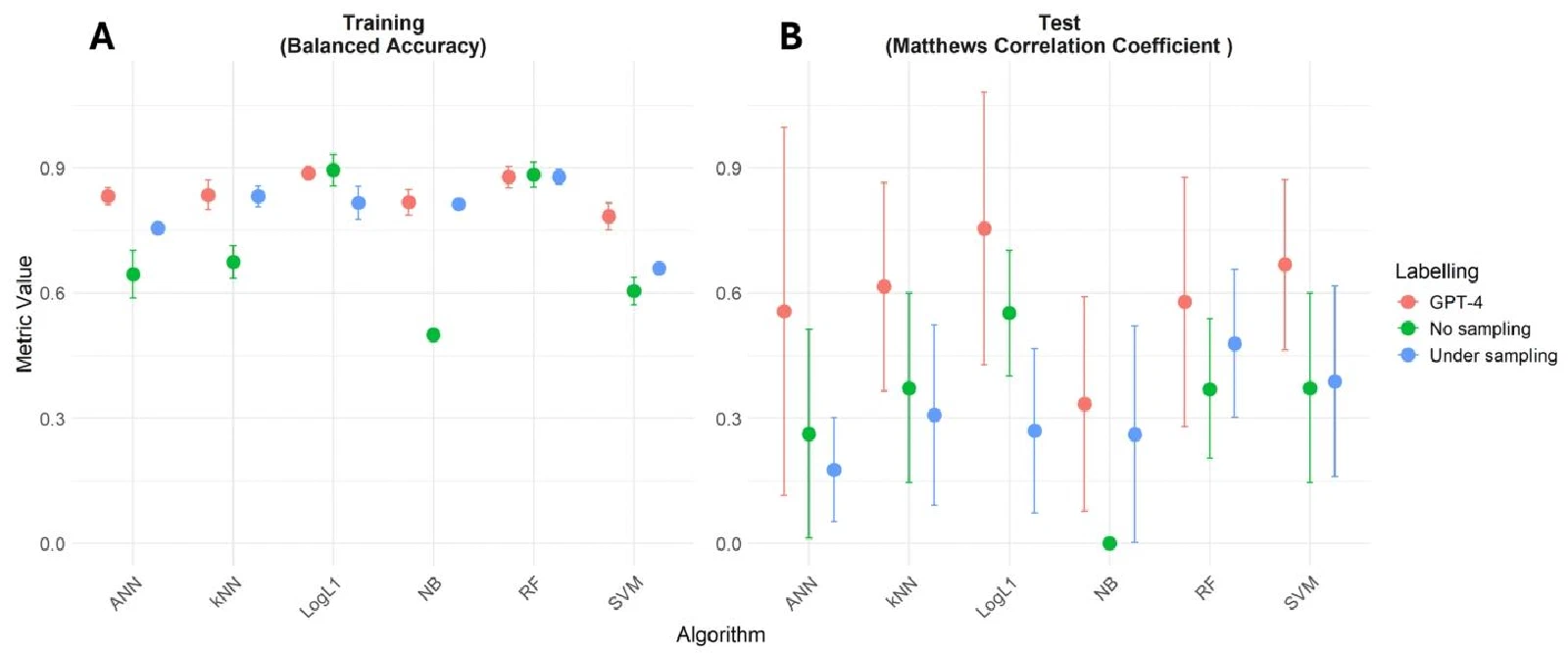
注意:这里没有改任何模型架构,提升完全来自数据质量。
路线三:LLM 作为直接推理者
DrugReAlign: a multisource prompt framework for drug repurposing based on large language models
不借助 GNN,直接用多源提示让 LLM 做推理。把药物的结构、靶点、已知适应症,疾病的生物标志物、发病机制,整合成结构化 prompt 输入模型,让 LLM 直接判断潜在关联。
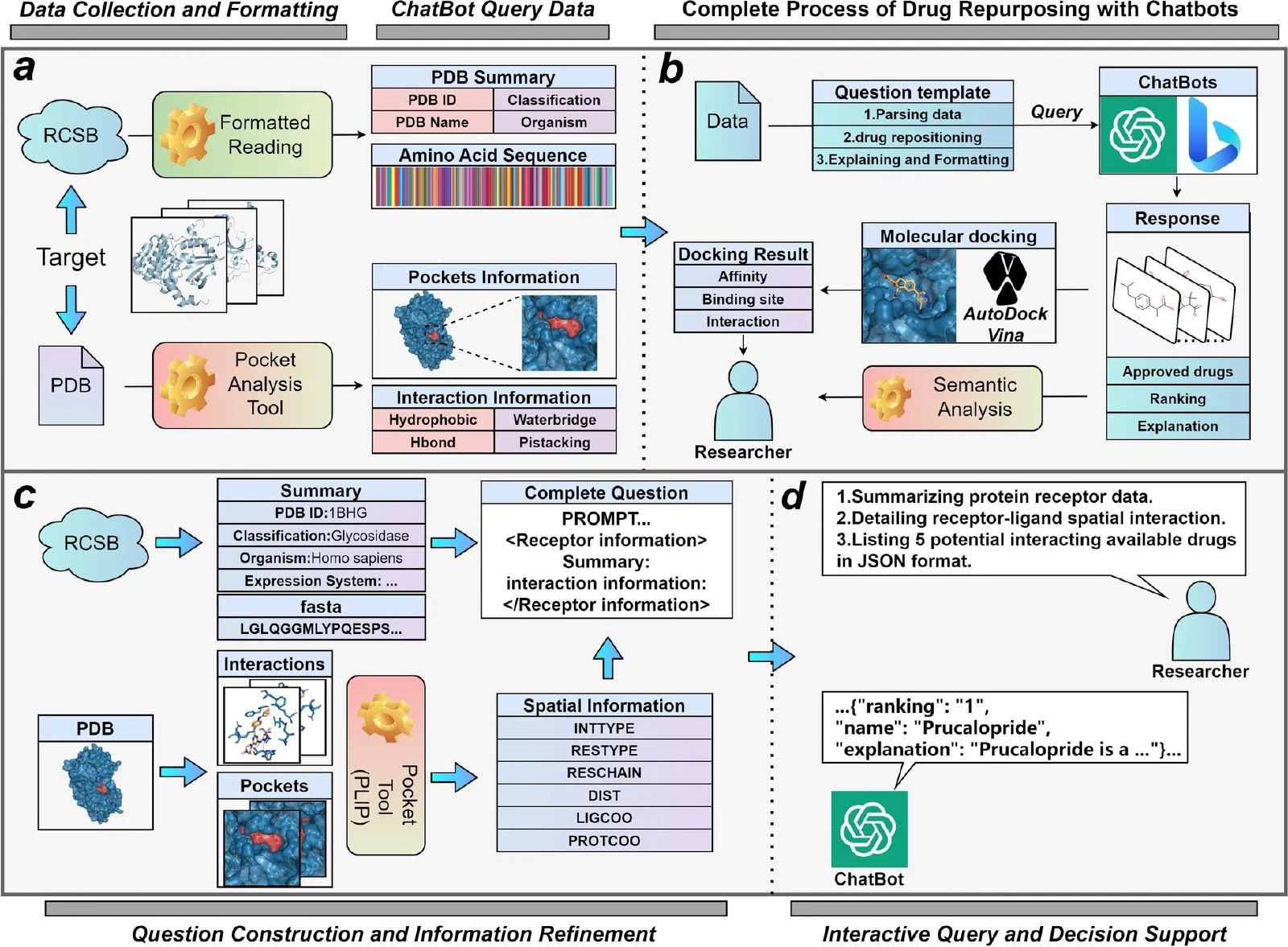
当时效果不如有 GNN 加持的方法,但方向值得关注:随着 LLM 推理能力增强,“不需要 GNN,直接问 LLM"可能越来越可行。
其他相关工作
- DrugGen:基于 DrugGPT 的分子生成模型,通过 SFT + PPO + RL 引导生成更高质量的分子,方向是 de novo 药物生成而非 repurposing
- BioBERT:生物医学领域的预训练语言模型,LBMFF 等工作的上游依赖
- LLM 化学任务基准:八项化学任务评测,零/少样本设定下 GPT-4 最优,Davinci-003 次之
个人判断
三条路线里,路线二(数据标注)最被低估。路线一的增量有限——LLM 嵌入 + GNN 确实比纯 GNN 好,但好多少取决于数据集,且引入了 GPT-4 API 调用的额外成本。路线三还不成熟。
路线二的逻辑更干净:与其设计更复杂的模型架构,不如先把训练数据清干净。临床试验记录里藏着大量被误标的数据,LLM 正好有能力读懂这些非结构化文本并做出判断。这和 RLHF 里用 LLM 做偏好标注是同一个思路——用语言模型的语义理解提升数据质量,而不是直接用它做预测。
药物重定位里真正稀缺的不是模型能力,而是高质量的标注数据,尤其是可靠的阴性。这个方向如果能扩展到其他适应症,比前两条路线更有实用价值。