SGLang, a Structured Generation Language for LLMs,论文如下:[2312.07104] SGLang: Efficient Execution of Structured Language Model Programs
解决的问题
尽管LM程序被广泛使用,但当前用于表达和执行它们的系统仍然低效。我们确定了与高效使用LM程序相关的两个主要挑战:
- 编写LM程序既繁琐又困难。开发LM程序通常需要大量的字符串处理、提示的实验性调整、脆弱的输出解析、处理多种输入模态以及实现并行机制。
- 由于大量计算和内存浪费,启动LM程序效率不高。
- Key-Value的重用策略不佳
- 结构化输出一个一个token预测,太慢了
基本框架
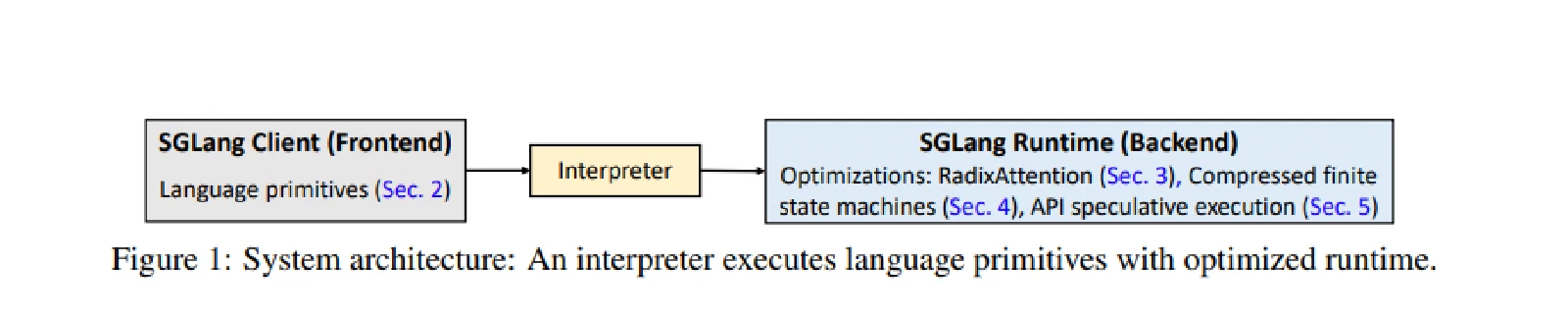
Frontend
- SGLang 是一种嵌入在 Python 中的领域特定语言(DSL,Domain Specific Language)
- 提供了针对 LLM 编程的原语,支持并行性、控制流、嵌套调用和外部调用
- SGLang 的设计目标是简化 LLM 程序的编写,并通过解释器、编译器和高性能运行时来提高执行效率
Interpreter
- 将前端代码转换为流式操作序列,异步提交给运行时
- 维护提示(Prompt)的中间状态(如对话历史、生成结果),确保多轮调用间的上下文一致性
- 支持将程序编译为静态计算图,进一步优化执行性能(如减少冗余计算)
Backend
- RadixAttention:用于在运行时自动重用 Key-Value(KV)缓存。该技术通过在基数树(radix tree)中维护一个最近最少使用(LRU)缓存,实现了多个生成调用之间的自动 KV 缓存重用。(在现有的推理引擎中,请求的KV缓存在处理完成后会被丢弃,这阻止了KV缓存在多次调用之间的重用,并显著减慢了执行速度)
- Compressed finite state machines(压缩有限状态机):实现更快的结构化输出解码。在可能的情况下将多标记路径压缩为单步路径,允许一次性解码多个标记,从而实现更快的解码速度(现有的系统仅遵循下一个标记的约束,通过屏蔽不允许的标记的概率来实现,这使得它们每次只能解码一个标记)
- API speculative execution (API 推测性执行):API推测性执行,以优化仅API模型的多调用程序
总的来说,后端的用处是解决加速问题。
Programming Model
运行实例

- 函数
multi_dimensional_judge接受三个参数:s、path和essay。 - 其中,
s管理提示状态,path是图像文件路径,essay是论文文本。 - 可以使用
+=操作符将新字符串和 SGLang 原语追加到状态s中以执行。 - 该函数首先将图像和论文添加到提示中,然后使用
select检查论文是否与图像相关,将结果存储在s["related"]中。 - 如果相关,则将
fork三个副本以并行评估不同维度,使用gen将结果存储在f["judgment"]中。 - 接下来,它合并评估结果,生成摘要,并分配字母等级。
- 最后,它以
JSON格式返回结果,遵循由正则表达式约束regex定义的模式
原语
SGLang 提供了用于控制提示状态、生成和并行性的原语。它们可以与 Python 语法和库一起使用。
gen:调用模型进行生产并存储在第一个参数指定的名称命名的变量中。支持正则实现结构化输出。select:调用模型从列表中选择概率最高的选项+=/extend:将字符串追加到prompt中[variable name]:获取生成的结果fork:并行分支join:重新连接提示状态image/video:图像/视频输入
执行模式
eager:最简单的是通过 Compiler,将 Prompt 视为异步执行流。像extend、gen和select这样的原语被提交到流中以异步执行。这些非阻塞调用允许 Python 代码继续运行,而无需等待生成完成,类似于异步启动 CUDA 内核。每个提示由后台线程中的流执行器管理,实现程序内并行性。获取生成结果会阻塞,直到结果准备好,以确保正确的同步。graph:可以被编译为计算图,通过图执行器执行,从而实现更多的优化
Efficient KV Cache Reuse with RadixAttention
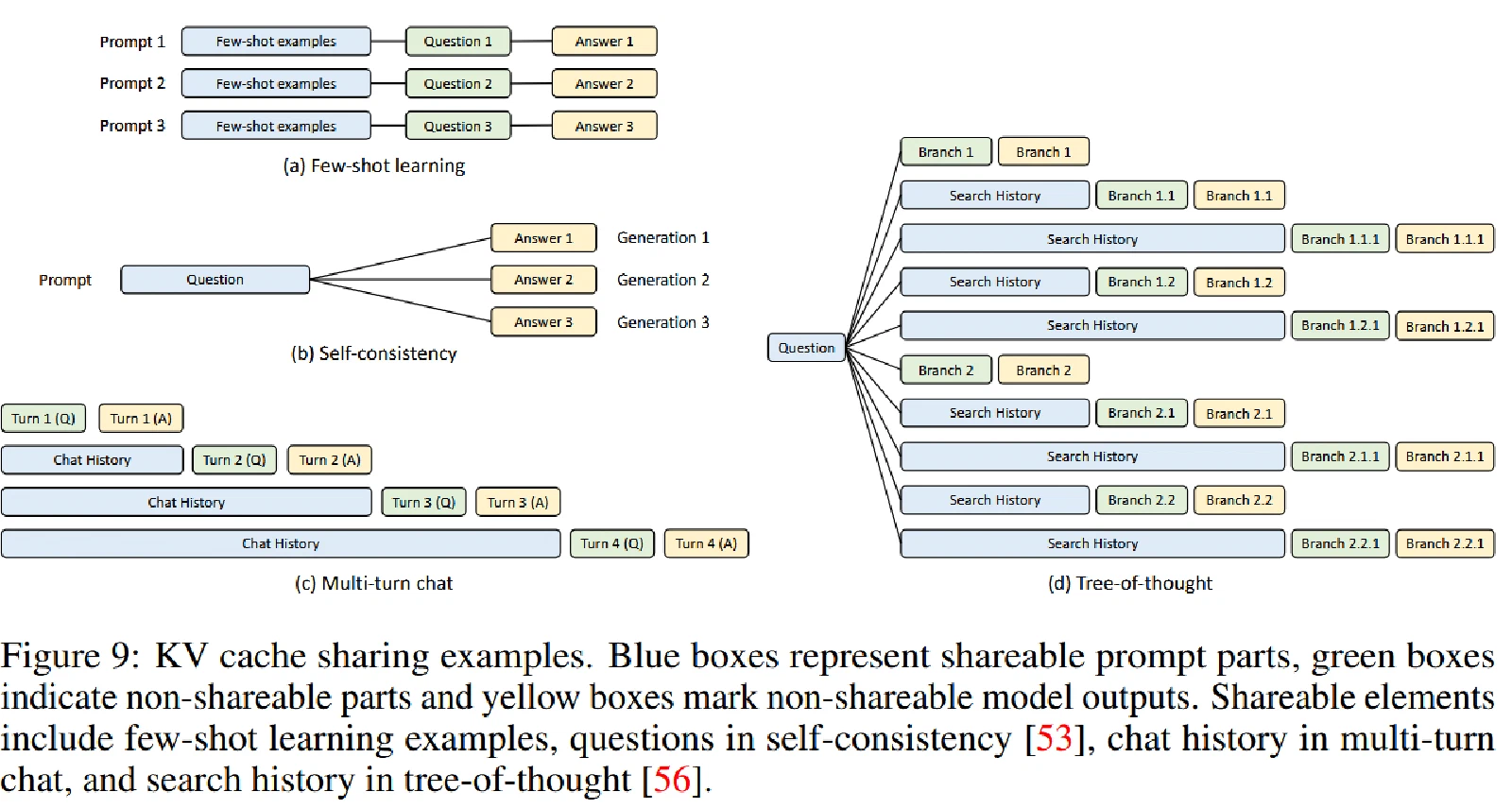
RadixAttention
KV cache经常需要重复使用:
- SGLang 程序可以将多个生成调用进行链式组合,并通过
fork原语创建并行副本。此外,不同的程序实例通常会共享一些公共部分(例如系统 Prompt)。这些场景在执行过程中会产生许多共享的 token 前缀,从而为 KV 缓存的重用提供了大量机会。 - 使用树结构维护历史的 KV cache,从而减少 prefix KV cache 的计算,达到减少 prefill 计算的效果;
- KV 缓存的计算仅仅取决于所有先前的 token,所以前缀相同的不同序列可以重复使用前缀标记的 KV 缓存,避免冗余计算。
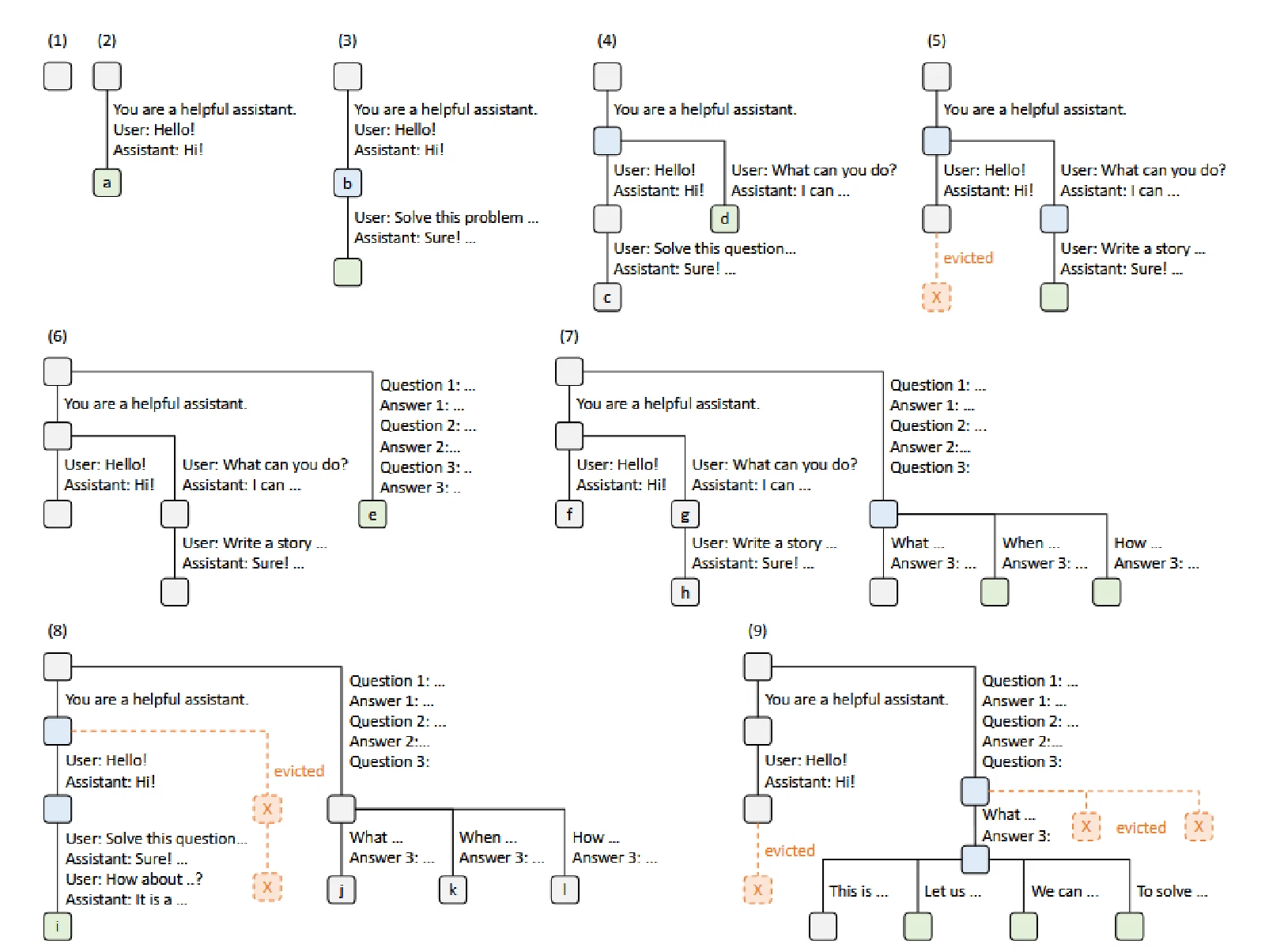
节点采用颜色编码以反映不同的状态:绿色表示新添加的节点,蓝色表示在该时间点访问的缓存节点,红色表示已被驱逐的节点。
在步骤(1)中,基数树最初是空的。
在步骤(2)中,服务器处理传入的用户消息“Hello”并以LLM输出“Hi”进行响应。系统提示“您是一个有用的助手”,用户留言“您好!”,LLM回复“您好!”作为链接到新节点的单边合并到树中。
在步骤(3)中,新的提示到达,服务器在基数树中找到该提示的前缀(即会话的第一轮)并重用其KV缓存。新的回合作为新节点附加到树中。
在步骤(4)中,新的聊天会话开始。 (3) 中的节点“b”被分成两个节点,以允许两个聊天会话共享系统提示。
在步骤(5)中,第二聊天会话继续。然而,由于内存限制,(4) 中的节点“c”必须被逐出。新的回合被附加在(4)中的节点“d”之后。
在步骤(6)中,服务器接收小样本学习查询,对其进行处理,并将其插入到树中。根节点被拆分,因为新查询不与现有节点共享任何前缀。
在步骤(7)中,服务器接收一批额外的小样本学习查询。这些查询共享同一组少数样本示例,因此我们从 (6) 中拆分节点“e”以实现共享。
在步骤(8)中,服务器从第一聊天会话接收新消息。它从第二个聊天会话中驱逐所有节点(节点“g”和“h”),因为它们最近最少使用。
在步骤(9)中,服务器接收到对来自(8)的节点“j”中的问题采样更多答案的请求,可能是为了自我一致性提示。为了为这些请求腾出空间,我们在 (8) 中逐出节点“i”、“k”和“l”。
缓存感知
对于请求的前缀长度排序,按深度优先搜索(DFS)顺序获得最佳的缓存命中率。
- 当等待队列中有许多请求时,它们的执行顺序对缓存命中率有显著影响。例如,如果请求调度器频繁地在不同的、不相关的请求之间切换,可能会导致缓存抖动和低命中率。
- 缓存感知调度策略的目的是提高缓存命中率。
也就是说,策略是:
- 在批处理设置中,按照匹配的前缀长度对请求进行排序,并优先处理匹配前缀较长的请求,而不是采用先到先得的调度方式;
- 最长共享前缀优先顺序等同于深度优先搜索顺序(DFS);
- 在线情况下,DFS顺序会被破坏,但调度仍然近似于在完整基数树的扩展部分上的DFS行为。
基于缓存感知的RadixAttention连续批处理调度
算法如下:

Data-Parallel Distributed RadixAttention
- Worker:维护自己的子树
- Router:负责管理一个元树,这个元树负责充当一个字典树,用于跟踪所有的子树和关联设备
具体来说:
- 新的请求到达 Router 时,会在元树上执行前缀匹配
- 根据每个请求的 affinity(通过与特定 Worker 和同一组中其他请求共享前缀的长度来衡量),Router 实施各种策略来做出高效的调度决策,以最小化冗余计算
- 每次处理新请求时,路由器和工作器都会独立更新各自的树。
- 如果 Worker 节点发生逐出(eviction),它会将此逐出提交到一个队列中。Router 会在活动量较低的时期处理此队列,以更新元树。
压缩有限状态机
有限状态自动机 - OI Wiki这篇wiki介绍了有限状态自动机,以及其和正则表达式之间的关系。
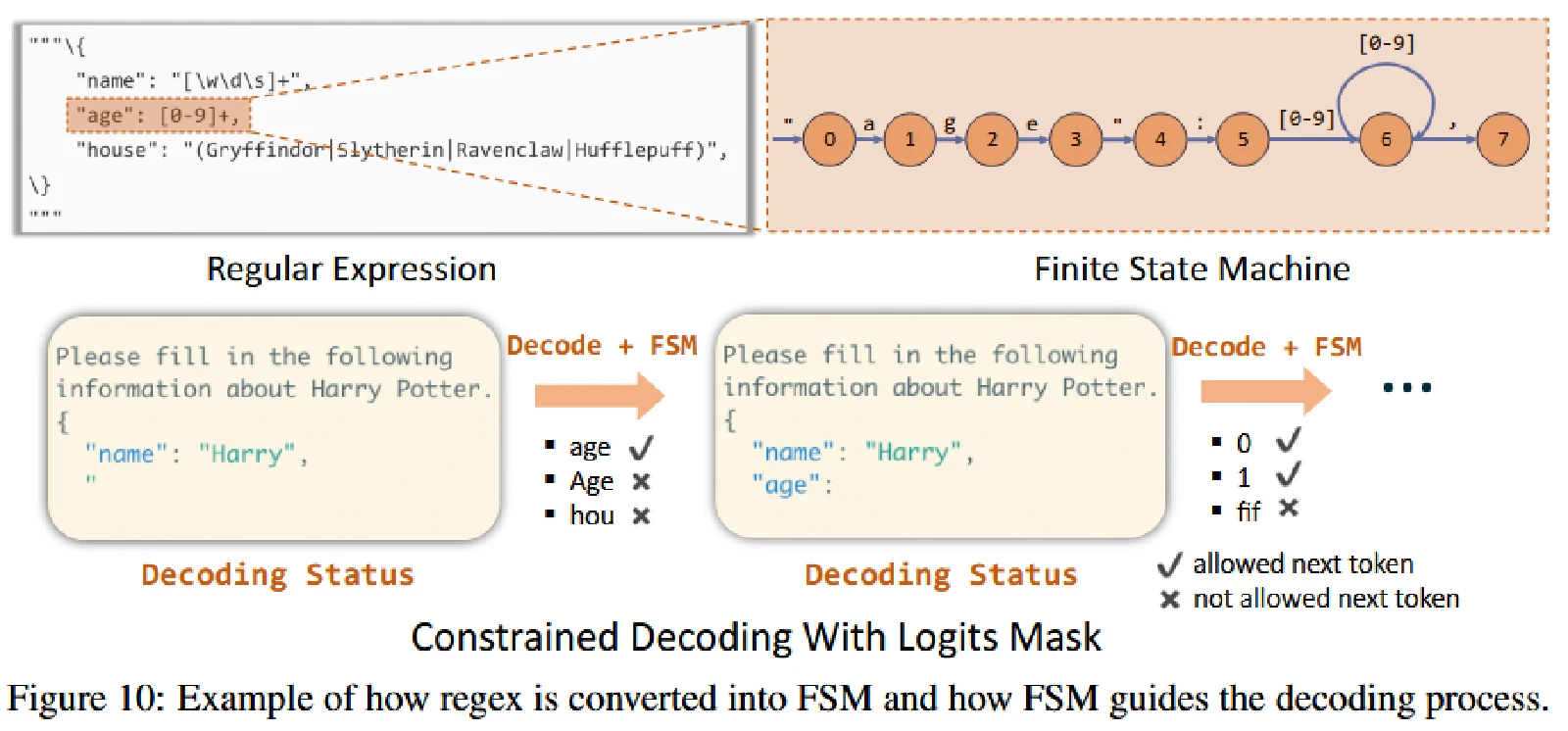
用户经常希望遵循约束模型的输出,如 JSON 格式,目前的系统基本用的方法是 Normal FSM,其解决方案是 decode 的时候将下一个状态的非法 token 的可能性设置为 0。
但是这存在一些问题:这个方法是逐个词元(token-by-token)地进行解码的。这意味着即使像 {“summary”: " 这种固定不变的字符串序列,它在模型内部可能由多个词元组成,现有系统也必须一个词元一个词元地处理,这非常低效。
而 SGLang 通过一个 fast constrained decoding runtime with a compressed FSM 解决此问题。把 FSM 中相邻的、只有一个转换路径的边(singular-transition edges)压缩成一条单一的边。这样就可以一次 decode 生成多个 token,大大加快了速度。
Fast JSON Decoding for Local LLMs with Compressed Finite State Machine - LMSYS Blog | LMSYS Org这里有一个博客可以参考,以供更深入的理解。
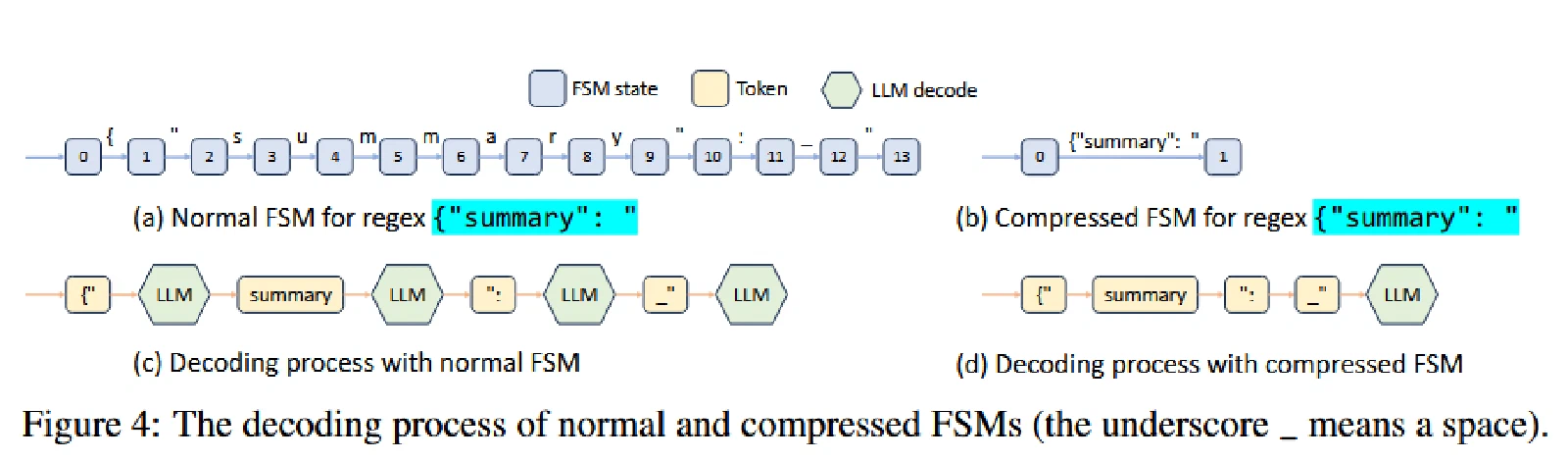
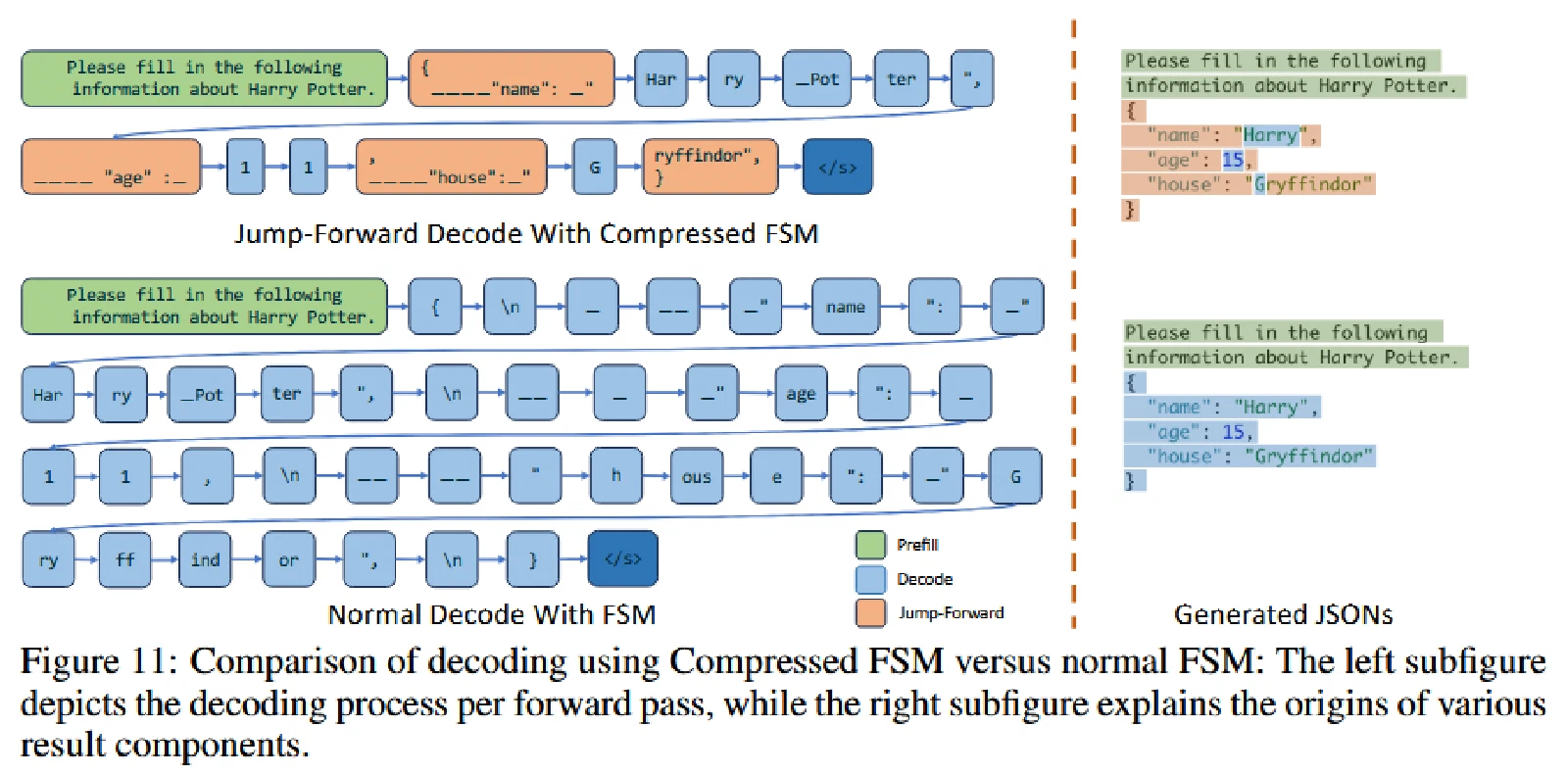
SGLang 提供了 regex 参数来提供正则表达式选择。
API Speculative Execution
前面的都是应用于开放权重模型,这里介绍了API调用情况下的优化。
- 在第一次 API 调用时延长生成: 当 SGLang 发出第一个
gen请求(例如,生成"name")时,它会忽略通常的停止条件。这意味着它会指示模型在生成完"name"之后,继续生成更多的 token,而不是立即停止。 - 解释器存储额外输出: SGLang 的解释器会捕获并存储模型在这次延长生成中产生的所有额外输出。
- 后续请求重用: 当程序遇到后续的
gen请求(例如,生成"job")时,SGLang 的解释器会首先检查它之前存储的额外输出。如果这些额外输出中包含了后续请求所需的信息(比如已经生成了"job"),那么它就会直接重用这些已有的输出。
性能评估
SGLang 是使用 PyTorch 实现的,并使用了来自 FlashInfer 和 Triton 的自定义 CUDA 内核。
开源模型结果
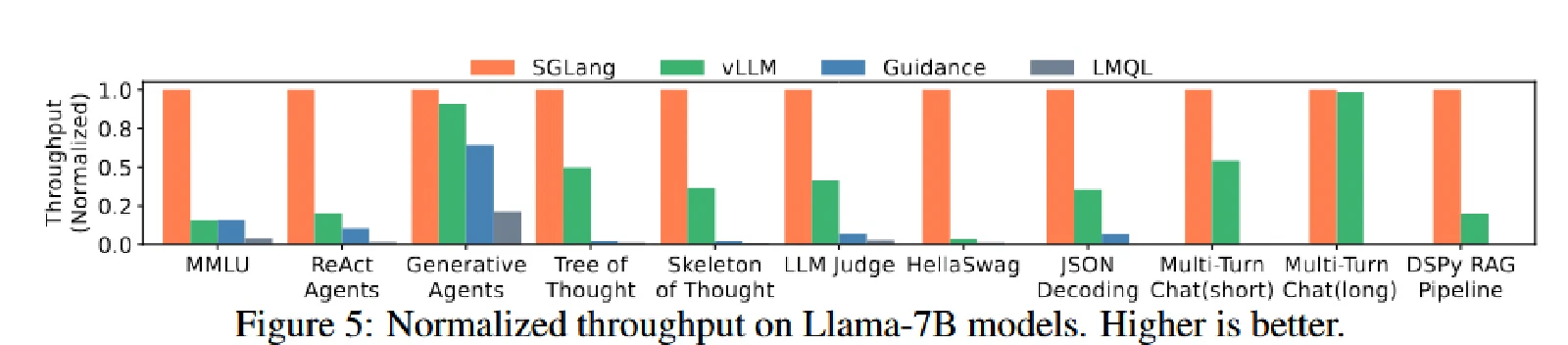
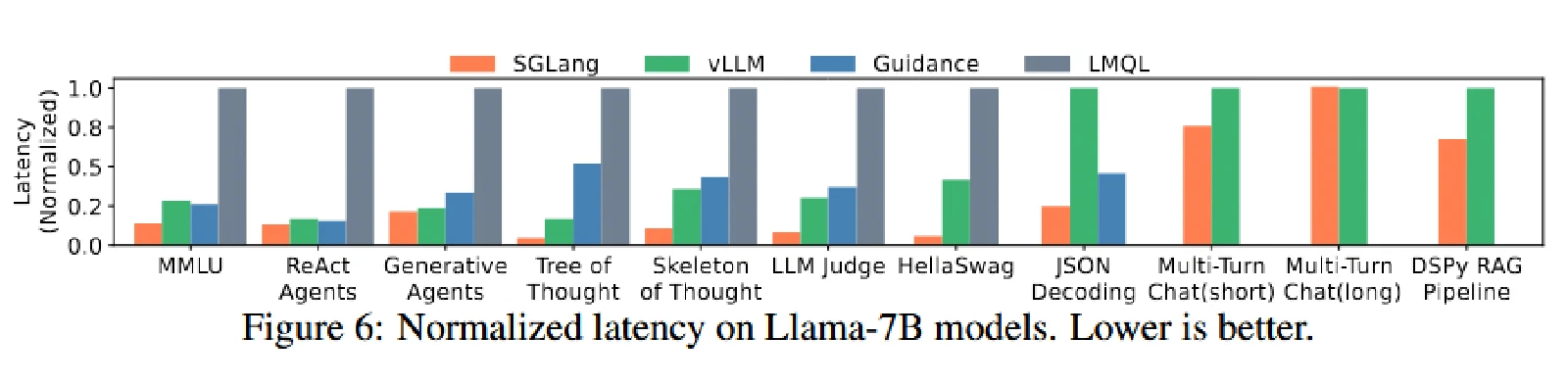
吞吐提高了6.4倍,延迟减少了3.7倍。
- RadixAttention:通过共享 KV 缓存减少总内存使用,从而支持更大的批处理量以提高吞吐量。它还减少了预填充(prefill)计算,降低了首个 token 的延迟。
- MMLU:利用 RadixAttention 重用 5-shot 示例的 KV 缓存。
- HellaSwag:对 few-shot 示例和多选问题的共同前缀进行 KV 缓存重用,实现了两级共享。
- ReAct 和生成式代理:重用代理模板和之前调用的 KV 缓存。
- Tree-of-thought 和 Skeleton-of-thought:在单个程序中并行化生成调用,并尽可能重用 KV 缓存。
- JSON 解码:通过压缩的有限状态机(FSM)同时解码多个 token,加速了解码过程。
- 多轮对话:重用聊天历史的 KV 缓存。这种加速对于短输出更为明显,因为 KV 缓存重用主要有助于减少前缀时间;对于长输出,由于共享较少且解码时间占主导,加速效果不显著。
- DSPy RAG 管道:重用通用上下文示例的 KV 缓存。
多模态张量并行结果
Mixtral-8x7B 和 Llama70B,结果呈现出和上面的开源小模型相当的加速。
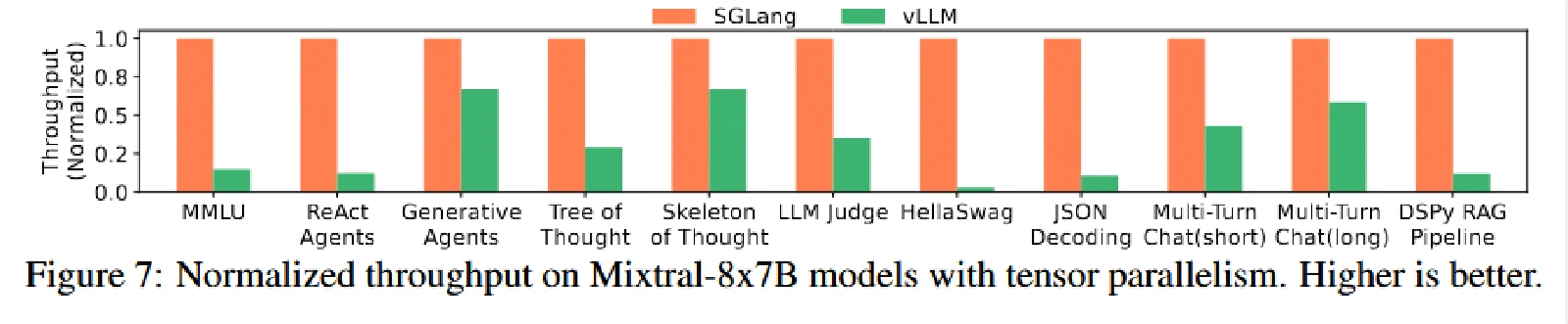
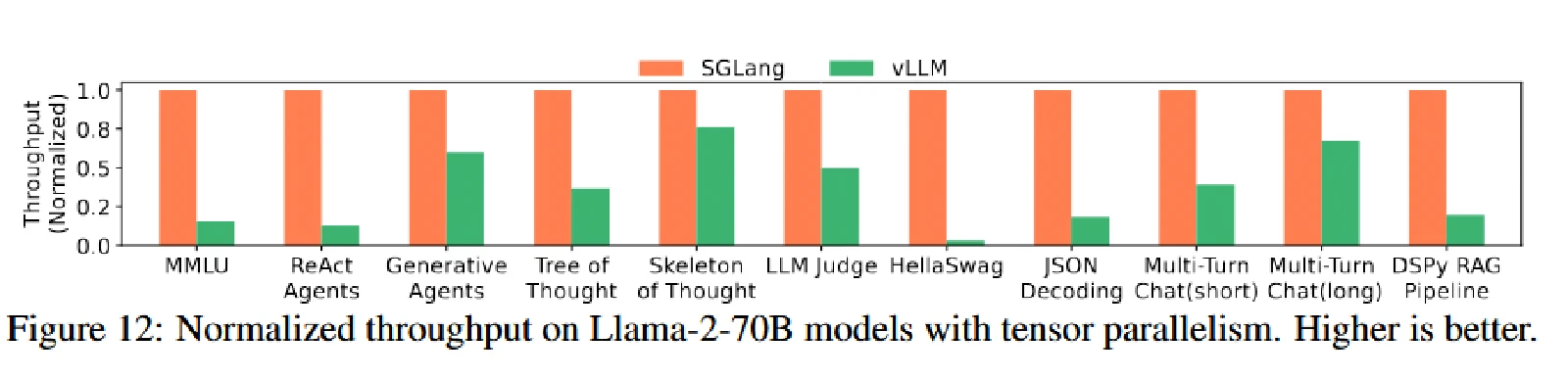
多模态大模型结果
SGLang 天然支持 image 和 video 的原语(将 image 计算 hash,将其 key 存入 Radix Tree 中,从而可以重复使用 KV cache)。
最高达到了6倍的加速。

生产部署
Chatbot Arena中已经部署,有些模型流量较低,因此只有一个SGLang worker提供服务。一个月后,发现缓存命中率较高。
API模型结果
测试了一个使用 OpenAI 的 GPT-3.5 模型从维基百科页面提取三个字段的提示。通过使用few-shot提示,API推测执行的准确性很高,并且由于提取了三个字段,因此将输入令牌的成本降低了约三倍。
消融实验
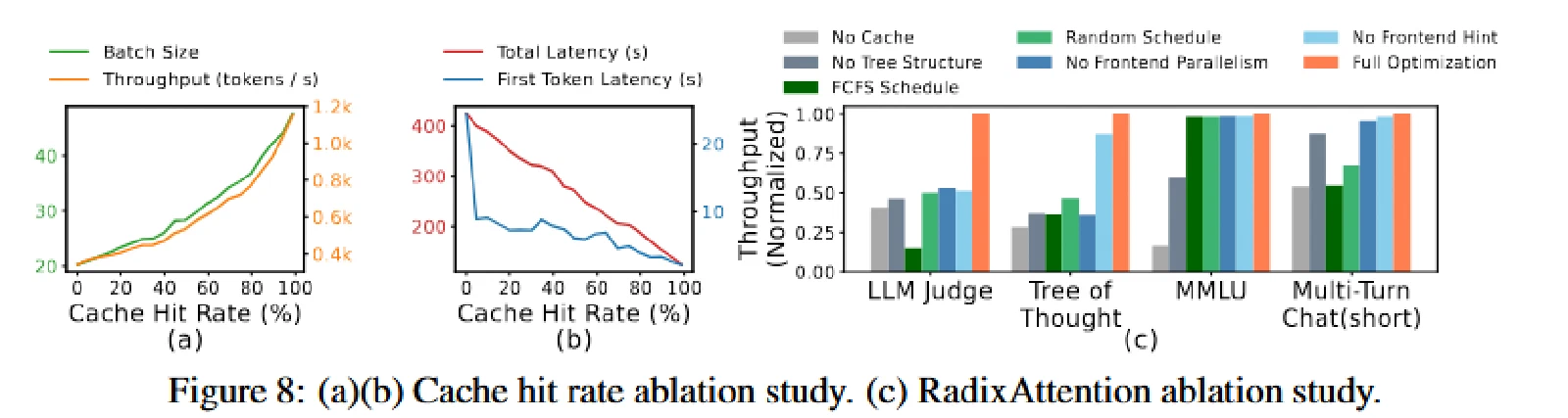
总结
SGLang的主要优势
- 前端可以优化LLM应用的编程模型,通过DSL和原语来简化编程
- 后端大幅优化运行速度
- Radix Attention机制:使用Radix Tree高效自动复用KV cache
- 压缩FSM:对有限状态机进行压缩
和其他框架的比较
未完待续