论文: Qwen-Image Technical Report
核心贡献: MSRoPE 多模态位置编码 + 双流 MMDiT 架构 + 复杂文本渲染 + 精确图像编辑
Qwen-Image 是通义千问系列中的图像生成基础模型,最亮眼的两个能力是复杂文本渲染和精确图像编辑。为应对复杂文本渲染的挑战,论文设计了一套精细的数据处理管线,确保模型能够准确生成图像中的文字内容。在图像编辑方面,模型支持基于指令的编辑操作,能够在保持主体身份的前提下完成局部修改和风格迁移。
模型架构
Qwen-Image 采用标准的双流 MMDiT(Multi-Modal Diffusion Transformer) 架构。文本和图像各有一条独立的 Transformer 流,每条流有独立的注意力计算,通过交叉注意力层进行模态间信息交换。
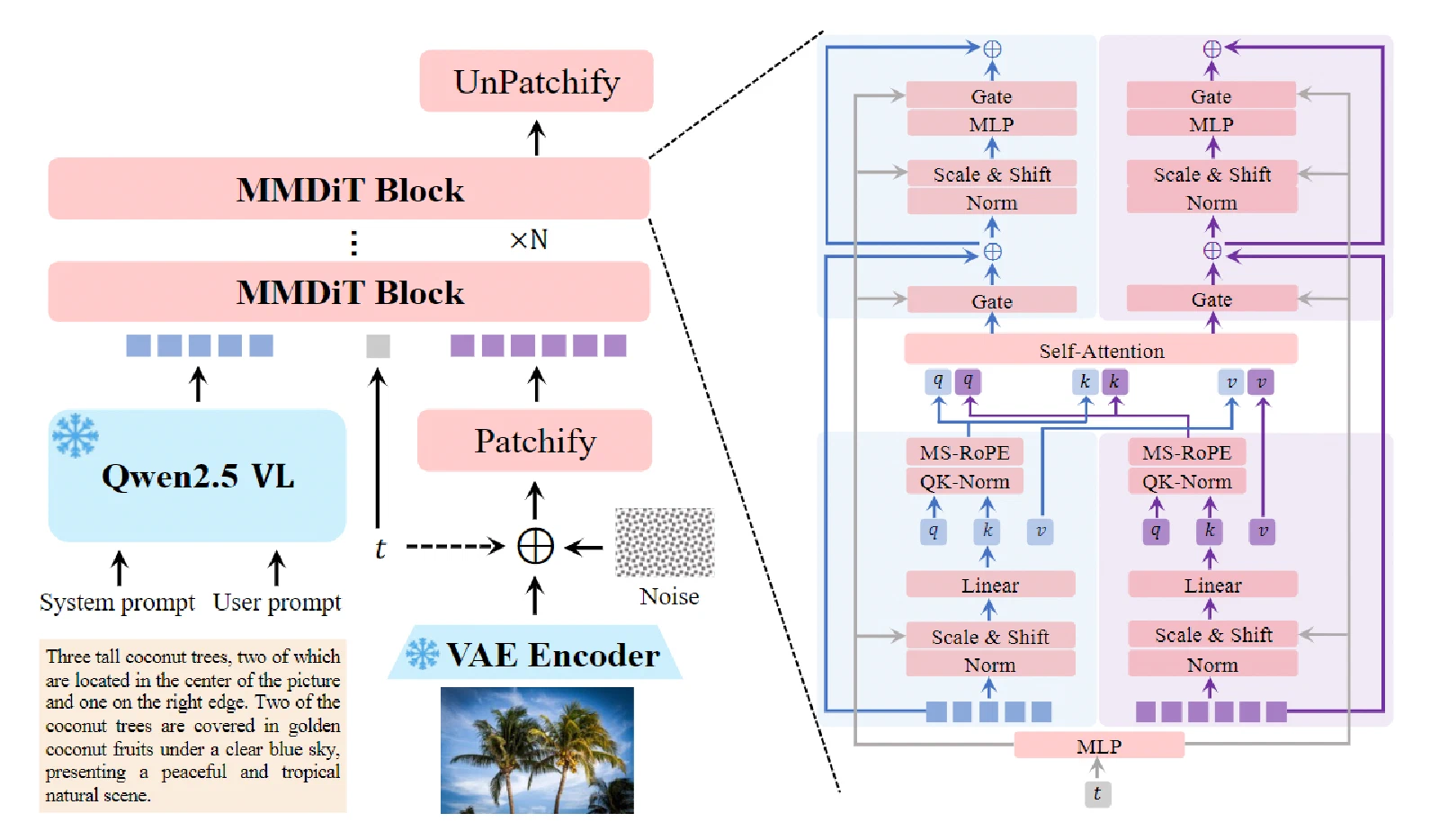
核心组件
核心组件是多模态大模型、VAE和MMDiT。
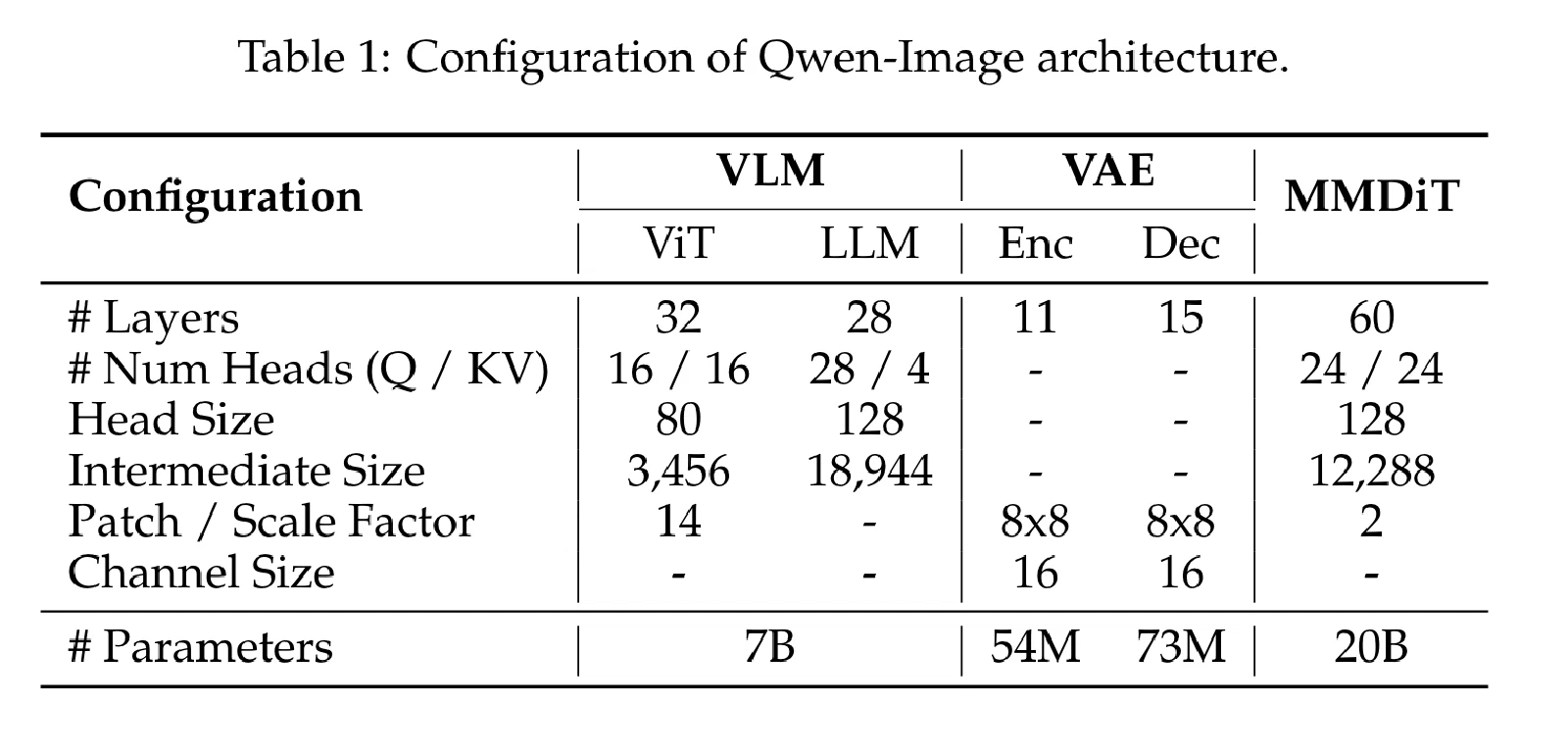
| 组件 | 具体实现 | 说明 |
|---|---|---|
| MLLM | Qwen2.5-VL(冻结) | 提取文本语义特征,通过投影层映射到扩散模型的嵌入空间 |
| VAE 编码器 | 8× 下采样 | 将原始像素压缩到潜在空间,提供图像的低维连续表示 |
| 文本流(Text Stream) | 独立 Transformer 层 | 处理文本 token 序列,保持文本语义的完整性 |
| 图像流(Image Stream) | 独立 Transformer 层 | 处理图像 patch token,执行扩散去噪过程 |
| 交叉注意力 | 流间交叉注意力层 | 两条流之间交换信息,实现文本对图像生成的精确控制 |
归一化策略:
- 在注意力计算的 Q 和 K 上使用 RMSNorm 进行 QK 归一化,防止注意力分数随模型规模增大而膨胀,稳定训练过程。
- 其他归一化层同样使用 RMSNorm 或 LayerNorm。
多模态大模型
使用Qwen2.5-VL。好处有以下几点:
- 文字和图像空间已经对齐
- 仍然有强大的语言建模能力
- 支持多模态输入
为纯文本输入和文本和图像输入设计了不同的系统提示。最后,我们利用 Qwen2.5-VL 语言模型主干的最后一层隐藏状态的潜在特征作为用户输入的表示。


VAE
使用single-encoder,dual-decoder的策略。
采用Wan-2.1-VAE的架构,冻结其编码器,并对图像解码器进行微调。为了提高重建保真度,特别是对于小文本和细粒度细节,我们在内部富含文本的图像语料库上训练解码器。
- 平衡重建损失与感知损失可以有效减少网格伪影,这种伪影经常在灌木丛等重复纹理中观察到。
- 随着重建质量的提高,对抗性损失变得无效,因为判别器无法提供有效的指导。
基于这些观察,我们仅使用重建和感知损失,在微调过程中动态调整它们的比例。
MMDiT
Multimodal Diffusion Transformer目前应该是最有效的一类之一,FLUX和Seedream都是用的此模型,本文也不例外。
本文提出了MSRoPE。
要解决的问题:
扩散 Transformer 中的位置编码面临一个固有矛盾:
- 图像 patch 是二维网格结构,需要 2D RoPE 来捕获空间关系。
- 文本 token 是一维序列,标准做法使用一维位置编码。
- 传统做法将文本 token 展平后拼接到图像位置嵌入之后,导致文本和图像在位置空间中处于不同的分布区域,难以精确建模文本对图像特定区域的细粒度控制。
Seedream 3.0 的改进尝试
Seedream 3.0 提出的 Scaling RoPE 对此做了改进:将图像的位置编码压缩到图像的中心区域,文本 token 被视为形状为 [1, L] 的二维 token,再用 2D RoPE 进行联合编码。MSRoPE 在此基础上做了进一步简化。
MSRoPE 的具体做法:
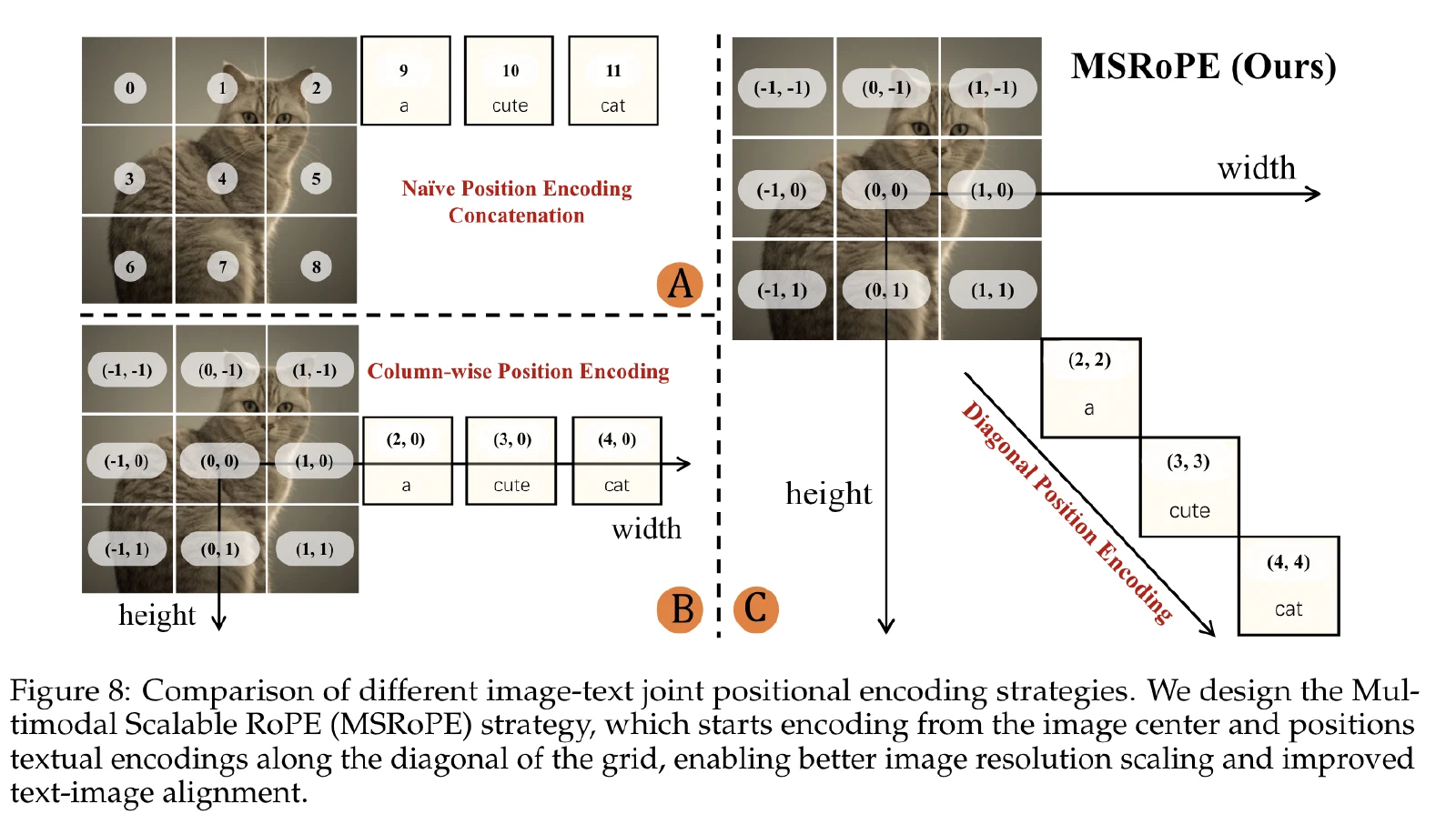
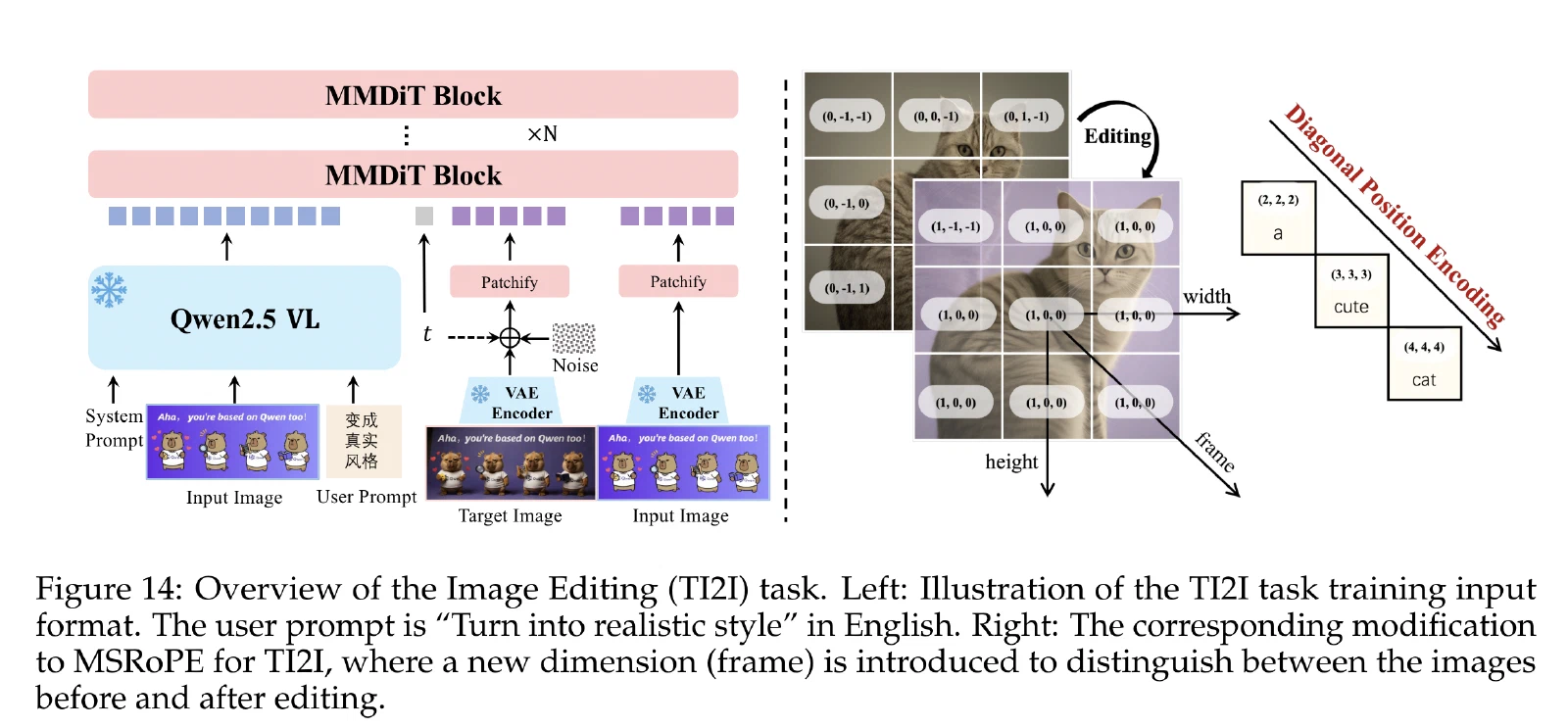
- 文本 token 提升为二维:将一维文本位置序列视为二维张量,在两个维度上使用相同的位置 ID。即对于位置为 $n$ 的文本 token,其二维坐标为 $(n, n)$。
- 对角线拼接:文本 token 沿着"对角线"方向与图像 patch 的位置编码进行拼接,使得文本和图像共享同一套 2D 坐标系。
- 多尺度旋转频率:通过调整 RoPE 的旋转频率基数,支持不同尺度的位置关系编码,使模型能够同时捕获全局布局和局部细节。
与文本展平后拼接的对比:
| 对比项 | 文本展平后拼接 | MSRoPE |
|---|---|---|
| 文本位置维度 | 1D 序列位置 | 2D 联合空间 |
| 图文对齐方式 | 分属不同空间 | 对角统一坐标系 |
| 细粒度定位 | 难以精确对应图像区域 | 自然支持 |
| 文字渲染 | 位置模糊,容易漂移 | 精确定位,不飘移 |
最终效果: MSRoPE 使得模型能够在统一的 2D 空间中精确地对文字进行位置编码,生成的文字能够准确出现在指定位置,且大小、方向与场景自然融合。
多任务框架
Qwen-Image 在统一的框架中支持三种任务类型:
| 任务 | 输入 | 输出 |
|---|---|---|
| 文生图(T2I) | 文本 prompt | 生成图像 |
| 图生图(I2I) | 参考图像 + 文本指令 | 编辑后的图像 |
| 图文生图 | 参考图像 + 文本 prompt | 融合生成的新图像 |
对于图像输入任务,模型的处理方式是:使用 Qwen2.5-VL 提取视觉 patches,通过 ViT 编码后与文本 token 拼接形成输入序列;同时,VAE 编码的图像潜在表示输入到图像流中。模型通过引入新的帧维度(frame dimension) 来扩展 MSRoPE,以区分输入图像和生成图像的位置。
数据准备
数据收集
准备了大量的数据集进行训练,比例如下:

多阶段数据清洗
论文构建了一套完整的数据清洗流程来确保训练数据质量。
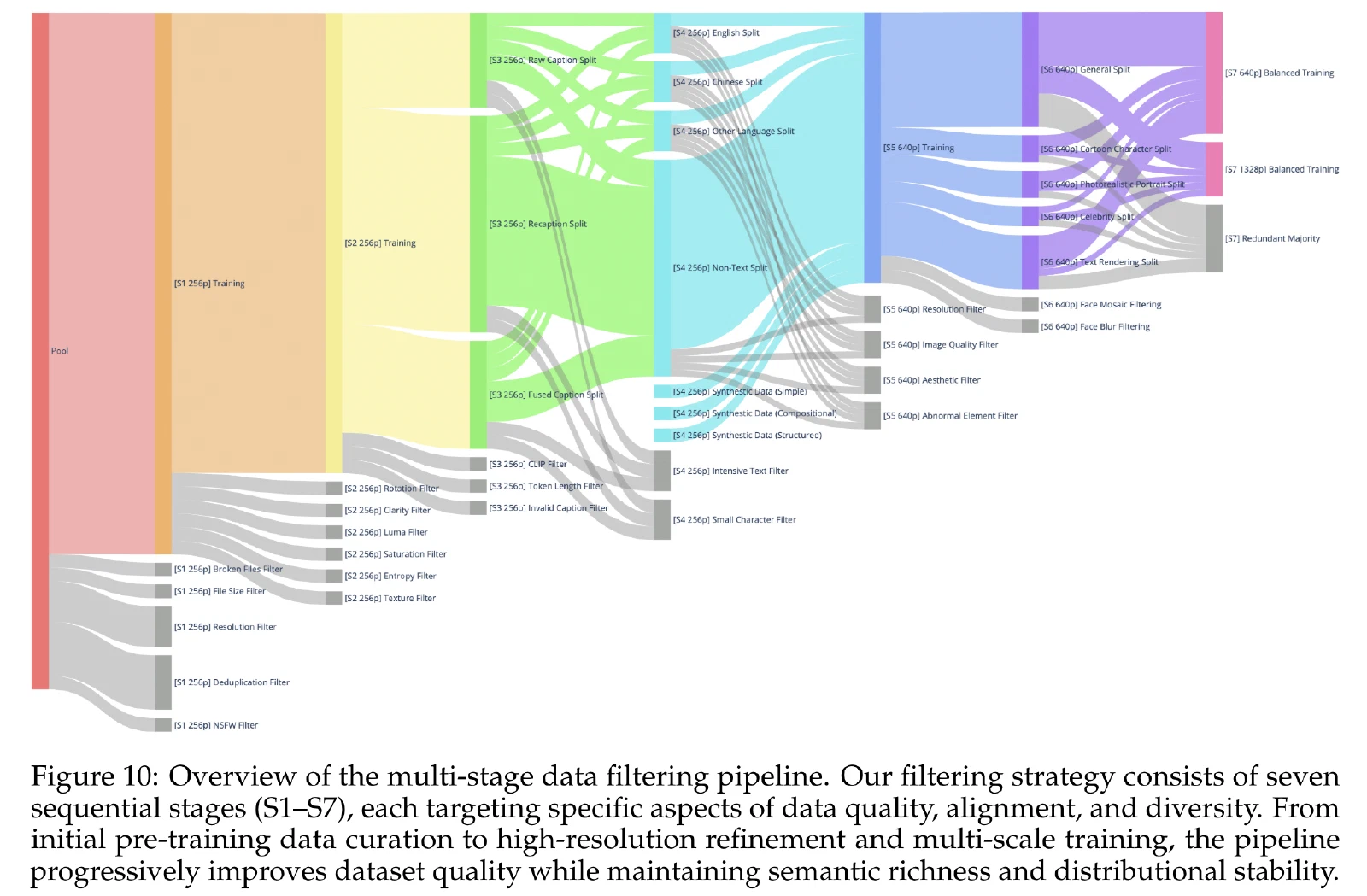
一阶段 — 初始预训练数据:
- 使用resize为256p的图像,去除低于此分辨率的,压缩高于此分辨率的
- 去除低质量或不相关图片
- 去除损坏文件
- 去除重复数据
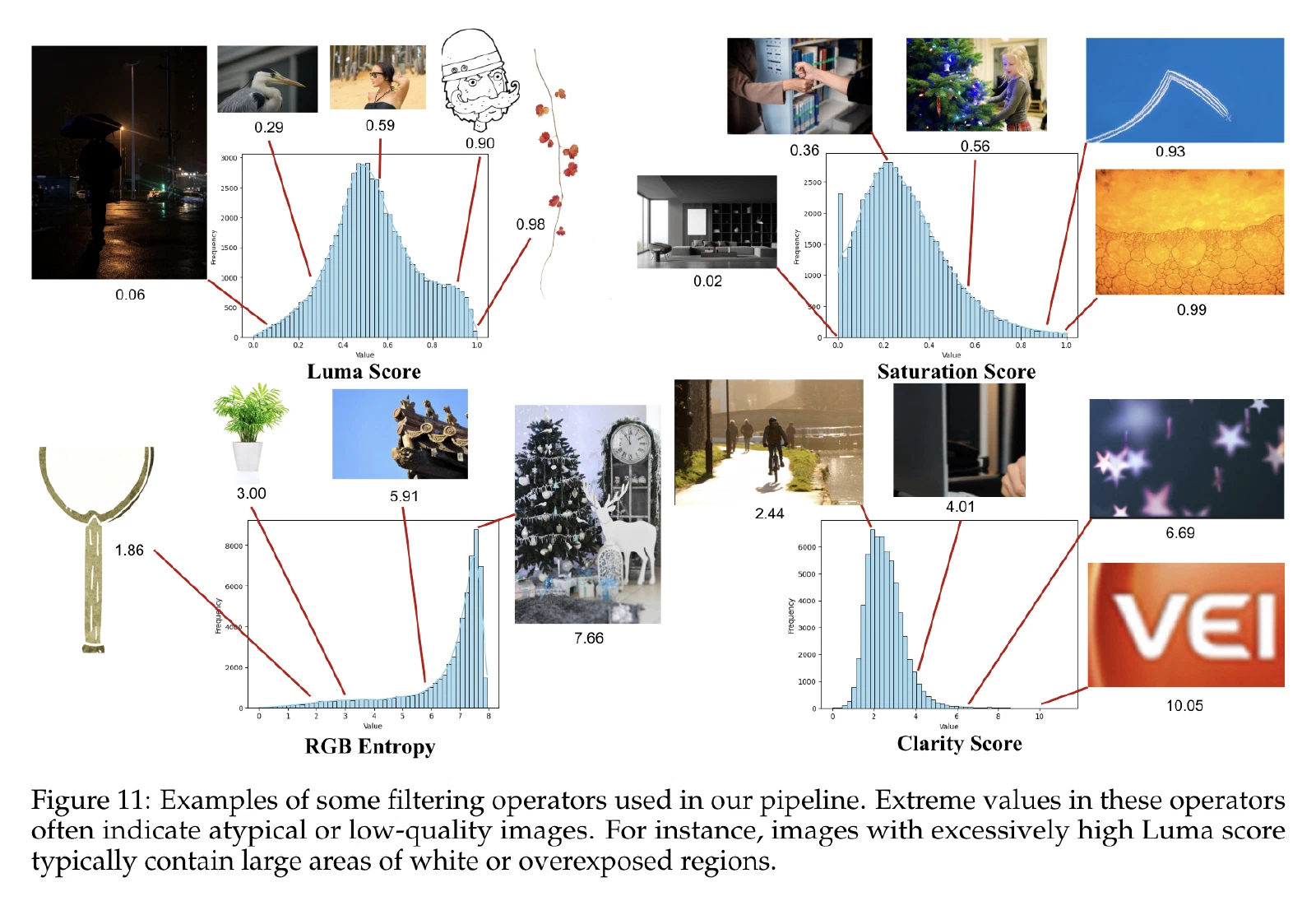
二阶段 — 质量筛选:
- 旋转:使用EXIF信息旋转
- 清晰度不佳
- 曝光错误
- 饱和度过高
- 熵过低
下图展示了具体的filter operator筛选的方法。
三阶段 — 图像-文本对改进: 将文本分成了三个部分:原始描述、重述和融合描述。
- 原始描述:有噪音但是带来了世界知识。
- 重述:由Qwen-VL Captioner生成的描述组成,提供更具有描述性和结构化的注释。
- 融合描述:将原始和生成的描述混合,提供通用知识和细节化描述。
- Chinese CLIP&SigLIP 2:移除描述不准确的图文
- 移除一些非法的、长度过长的描述
四阶段 — 文本渲染增强:
- 第三阶段的数据集被分为四个分割:英语分割、中文分割、其他语言分割和非文本分割,以确保不同语言环境下的平衡训练。
- 使用了合成文本渲染数据
- 密集文本Filter和小字符Filter去除过小的图像
五阶段 — 高分辨率细化:
- 使用640p图像训练
- 图像质量Filter去除有质量问题的图像,如曝光、模糊或伪影
- 审美Filter去除构图或视觉吸引力较差的图像
- 异常元素Filter去除含有水印、二维码、条形码或其他可能干扰查看的元素的图像
六阶段 — 类别平衡和肖像增强:
- 将数据集分成三种类别:常规、肖像和文本渲染
- 关键字retrieval和图像retrieval通过目标patch来扩充数据集:从人物类别中检索逼真的肖像、卡通人物和名人图像。然后生成合成字幕以强调特定于角色的细节
七阶段 — 平衡多尺度训练:
- 在640p和1328p上联合训练
- 分层分类:受 WordNet 设计原则的启发,分类中只保留具有最高质量和审美吸引力的图像
- 重采样:采用专门的重采样策略来平衡包含文本渲染的数据,解决token频率的长尾分布问题
数据标注
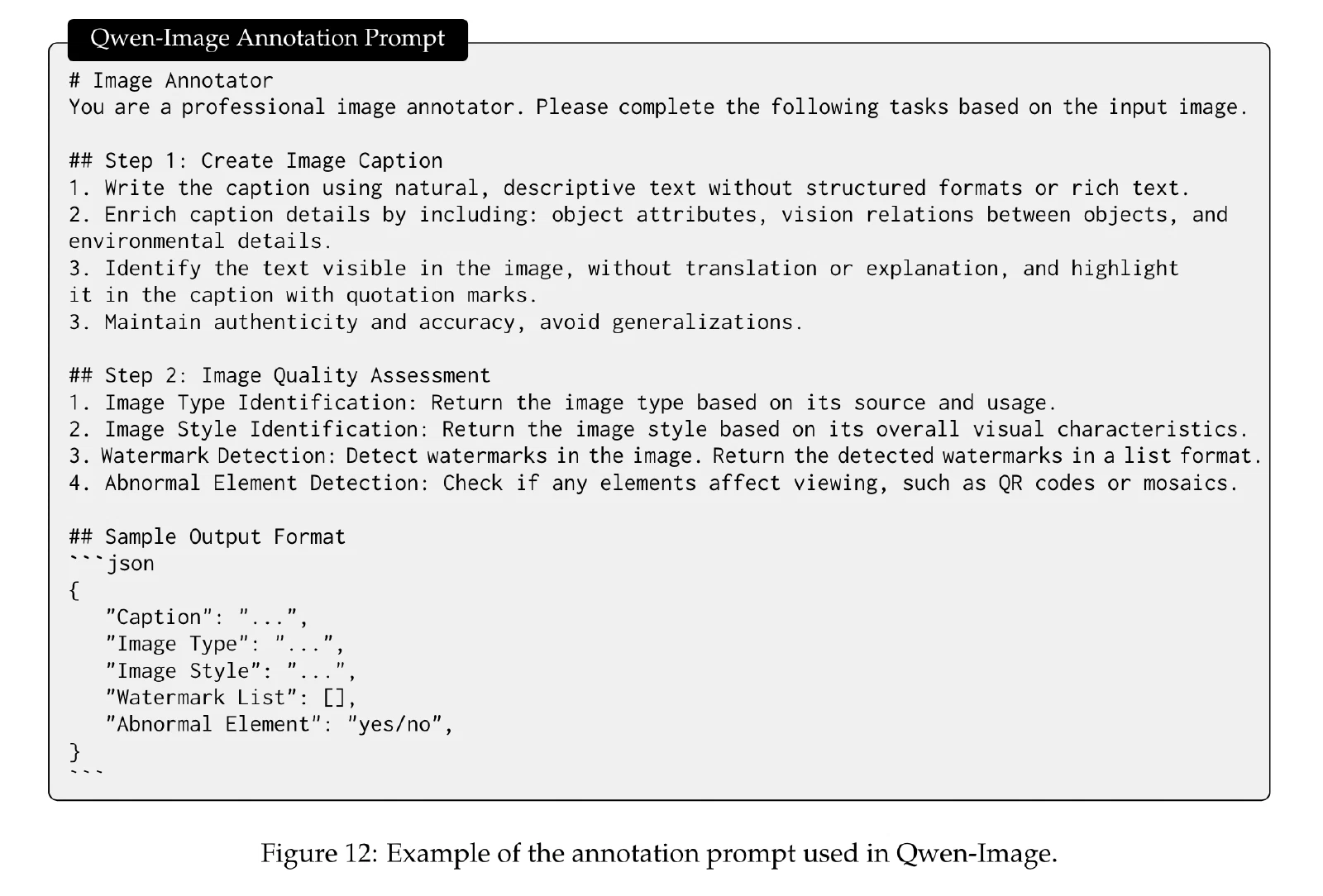
利用功能强大的图像描述生成器(例如 Qwen2.5-VL)不仅生成全面的图像描述,还生成捕获基本图像属性和质量属性的结构化元数据。
数据合成
多阶段文本感知图像合成pipeline,集成了三种互补策略:纯渲染、合成渲染和复杂渲染。
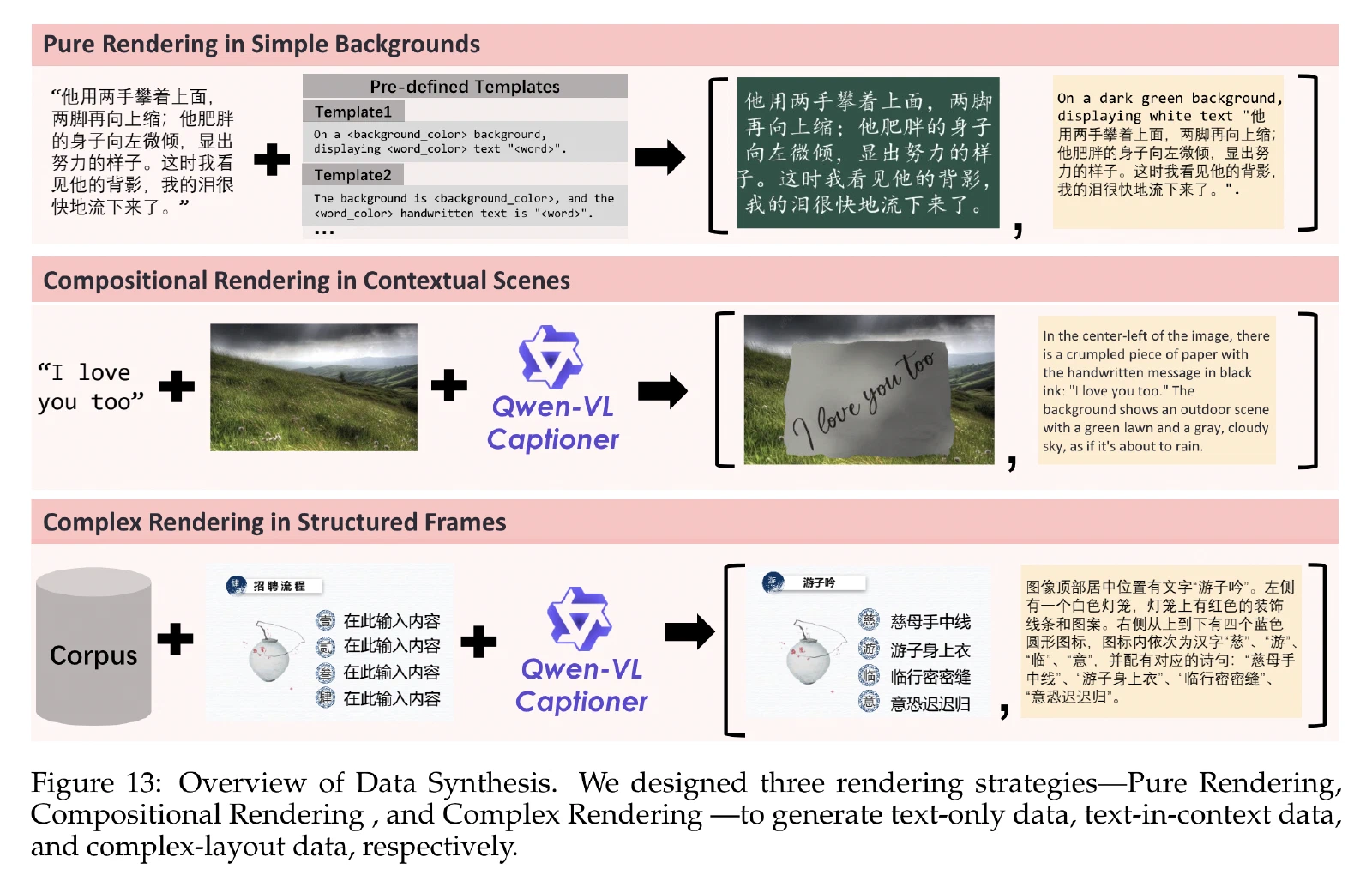
简单背景下的纯渲染:模型识别生成字符最有效的方法。如果段落中的任何字符由于限制(例如字体不可用或渲染错误)而无法渲染,则整个段落将被丢弃。
上下文场景下的合成渲染:合成文本嵌入到现实的视觉环境中,模仿其在日常环境中的外观,比如纸张、木板等,然后无缝地合成到不同的背景图像中。
结构化模板下的复杂渲染:基于预定义模板(例如 PowerPoint 幻灯片或用户界面模型)的编程编辑的综合策略。
训练
预训练
Qwen-Image 采用 Flow Matching(FM) 作为训练目标,而非传统扩散模型的噪声预测。
下图是用AI生成的示意图。
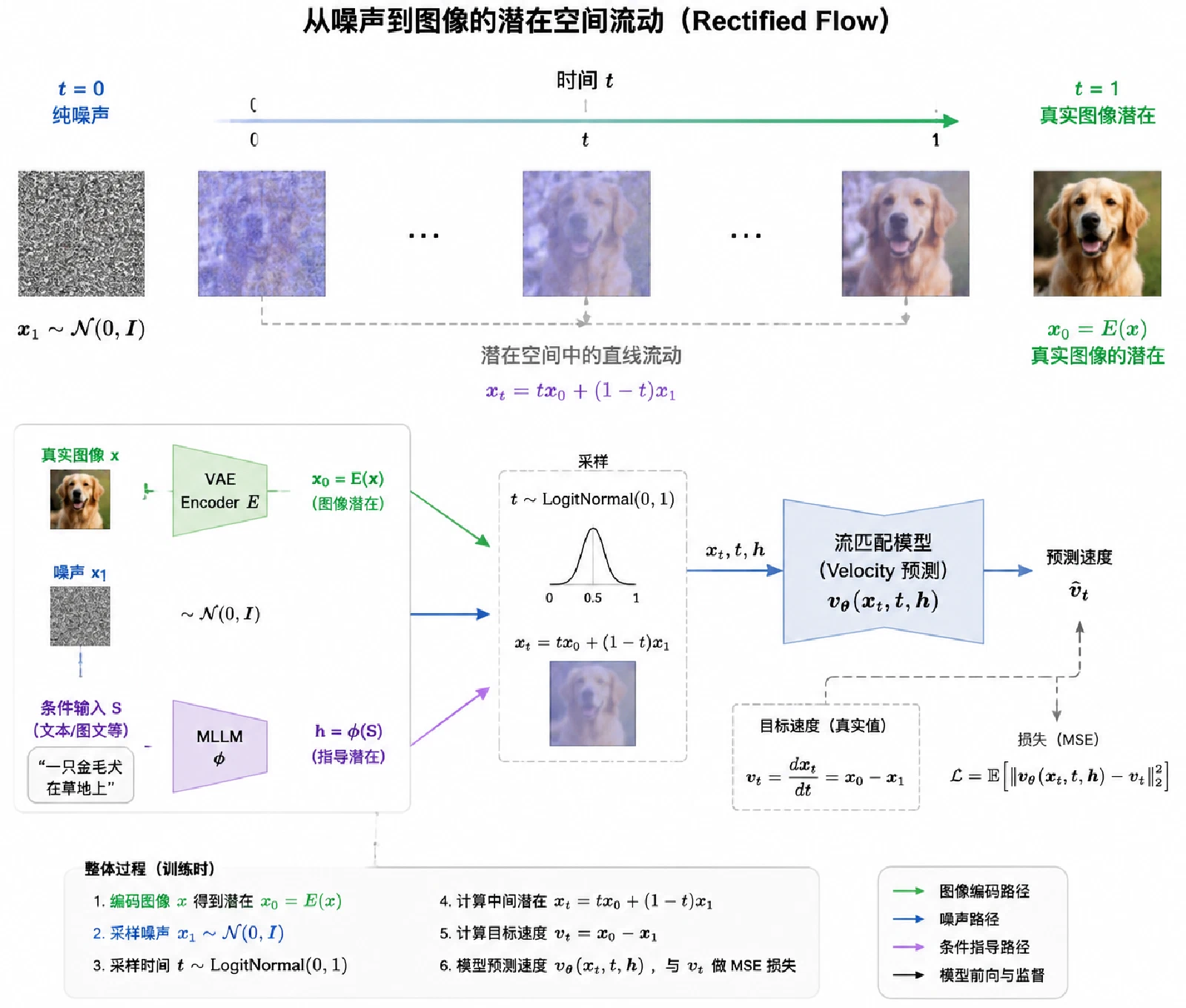
Producer-Consumer框架
受到 Ray分布式框架的启发:
**Producer 的任务是把原始数据处理好,让 GPU 可以直接训练。具体步骤如下:
- 数据筛选:
- 根据预定义标准过滤图像-文本对,比如图像分辨率、是否符合检测规则等。
- 编码成潜在表示(Latent Representation):
- 使用 MLLM 模型(如 Qwen2.5 VL)和 VAE 对图像进行编码。
- 这样可以减少数据量,并加速训练。
- 缓存与分组:
- 将处理好的图像按分辨率分组,存入高速缓存(cache buckets)。
- 存储在一个共享的、位置感知的存储系统(location-aware store),让消费者可以快速获取。
- 与 Consumer 连接:
- 使用 HTTP 传输层实现通信。
- 支持 RPC(远程过程调用)语义 和 零拷贝调度(zero-copy scheduling),可以异步传输数据而不浪费内存。
Consumer 专注于模型训练:
- 训练节点部署在 GPU 密集型集群上。
- 专注计算:因为数据处理都在 Producer,Consumer 只需用 GPU 训练 MMDiT 模型。
- 参数分布:
- 模型参数使用 4-way tensor-parallel(张量并行)分布在多个 GPU。
- 异步拉取数据:
- 每个数据并行组(data-parallel group)可以直接从 Producer 拉取预处理好的批次(batches),无需等待。
分布式训练
由于参数量较大,无法仅使用 FSDP 将模型加载到单块 GPU 上,采用了 Megatron-LM 进行分布式训练:
- 混合并行策略:数据并行(Data Parallelism)+ 张量并行(Tensor Parallelism),使用 Transformer-Engine 库实现高效计算。
- 分布式优化器:使用分布式优化器减少显存占用。
- 激活检查点(Activation Checkpointing):初期使用,后期随着优化器优化关闭激活检查点,仅依赖分布式优化器来降低通信开销。
分阶段训练策略
- 提高分辨率:从低分辨率到高分辨率
- 集成文本渲染:从非文本到文本
- 精细化数据质量:从海量数据到精细化数据
- 平衡数据分布:从不平衡到平衡
- 使用合成数据进行增强:从真实世界数据到合成数据
后训练
SFT
- 高质量数据集:分层组织的语义类别数据集,覆盖多种场景和风格。
- 人工标注:细致的人工标注和审核流程,针对模型在实际应用中的不足进行有针对性的优化。
- 图像清晰、细节丰富、明亮且逼真。
RL
采用两阶段强化学习策略:
**DPO
基本思路是:对同一 prompt,人工选择最好和最差的生成图像,基于 Flow Matching 的似然函数构造 DPO 目标函数,将偏好信号直接融入生成轨迹优化中。
- 应用规模:在大规模偏好数据集上应用,快速对齐模型与人类偏好。
- 优化目标:提升模型生成"好图"的概率,降低生成"差图"的概率。
**GRPO
我们按照 Flow-GRPO 使用 GRPO 进行进一步的细粒度训练。
- 采样:从当前策略(模型)中采样多组生成图像。
- 评估:使用多个专用奖励模型(美学评分、文字渲染精度、编辑一致性等)对每组图像进行打分。
- 优化:在小规模、高质量的数据上进行精细化调整。
多任务训练
除了文生图之外,还有多模态图像生成任务,支持了输入文本+图像作为Qwen-Image MMDiT的输入。
实验
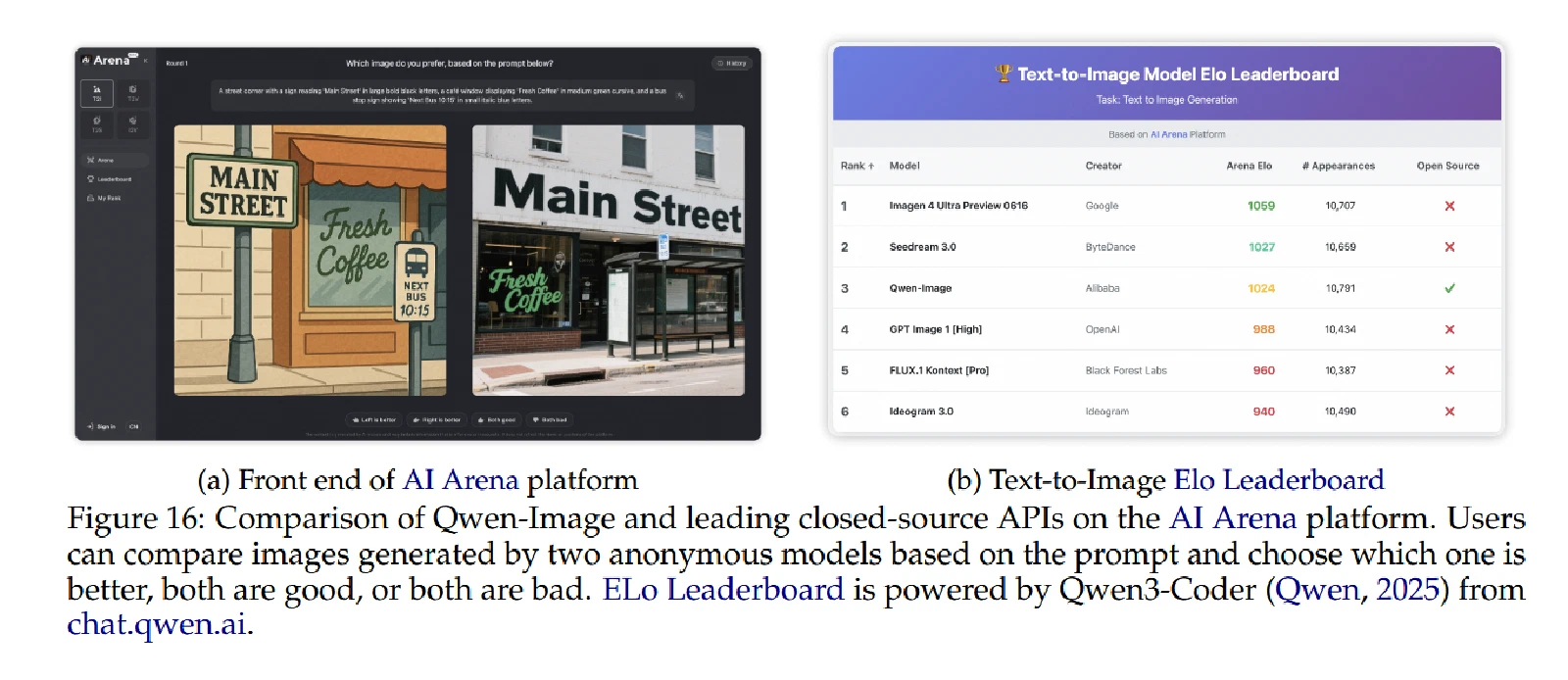
人类评价
AI Arena2,这是一个基于 Elo 评级系统(Elo &Sloan,2008)构建的开放基准测试平台。由用户选出其中较好的一个。
和Imagen 4 Ultra Preview 0606、Seedream 3.0、GPT Image 1[HIGH]、FLUX.1 Kontext [Pro]比较,排名第三。
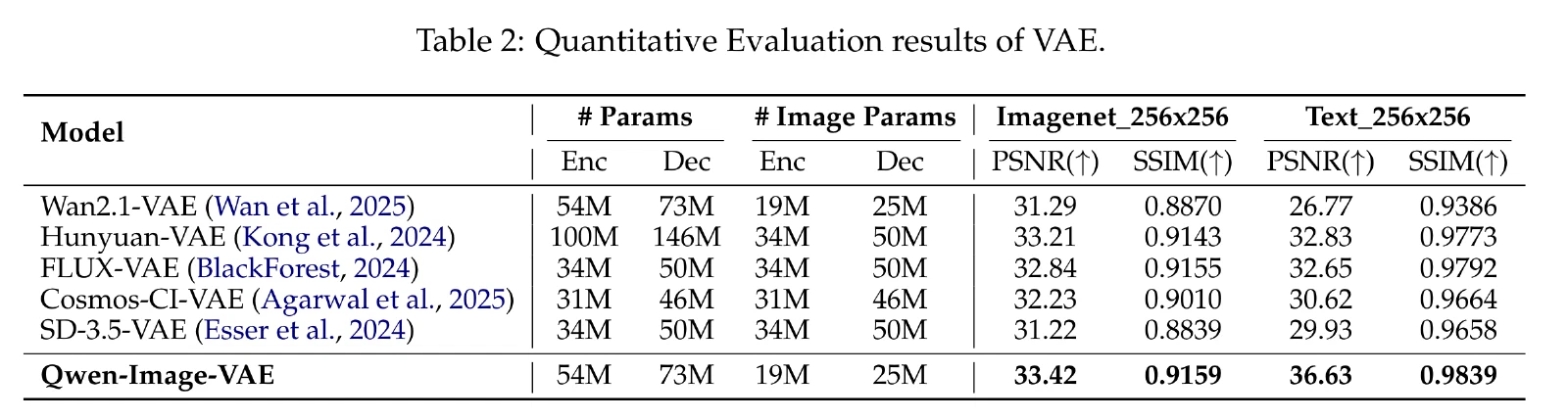
量化指标
VAE重建表现
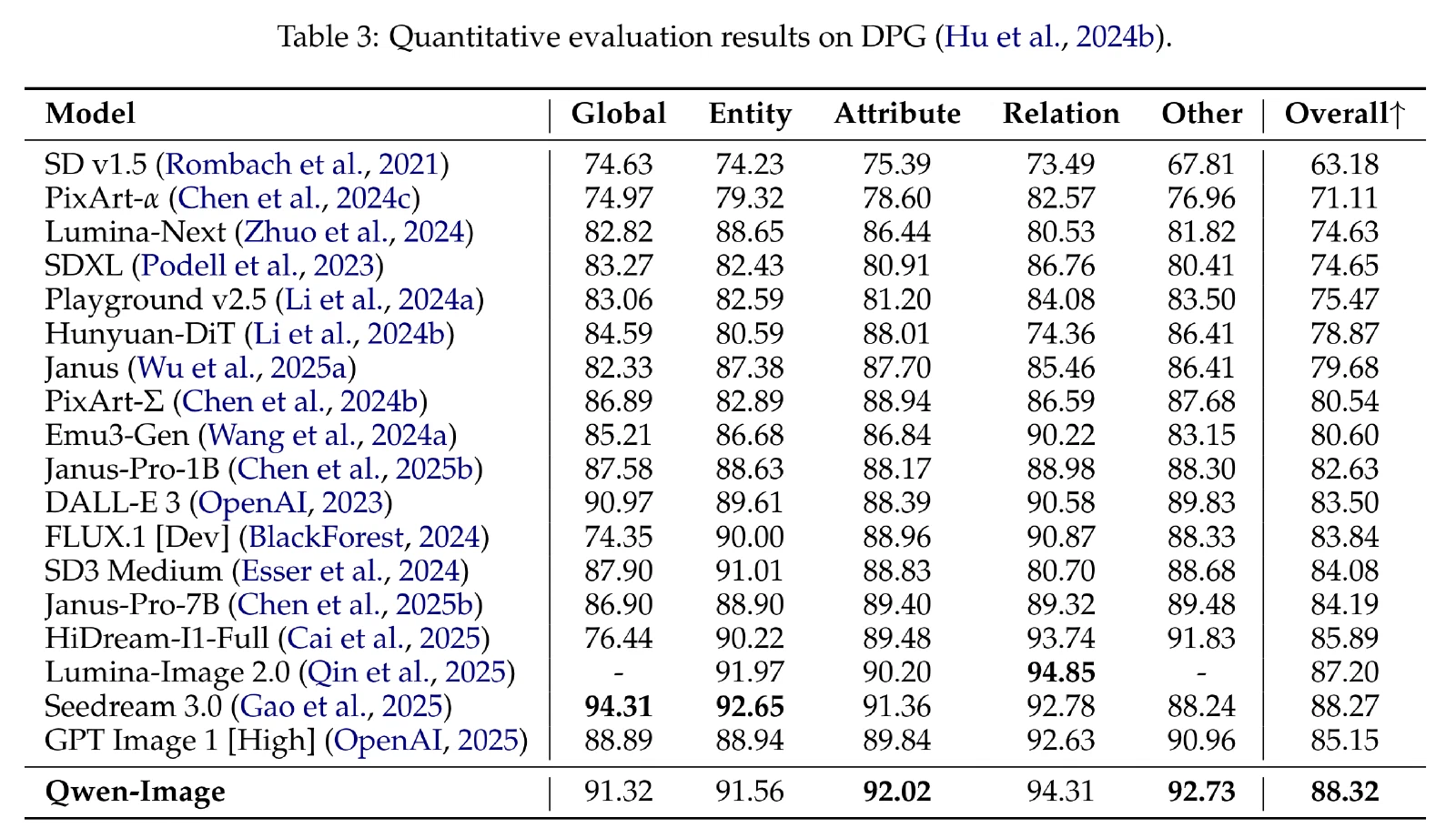
文生图表现
DPG:该基准测试由 1K 密集提示组成,可以对提示遵守情况的不同方面进行细粒度评估。
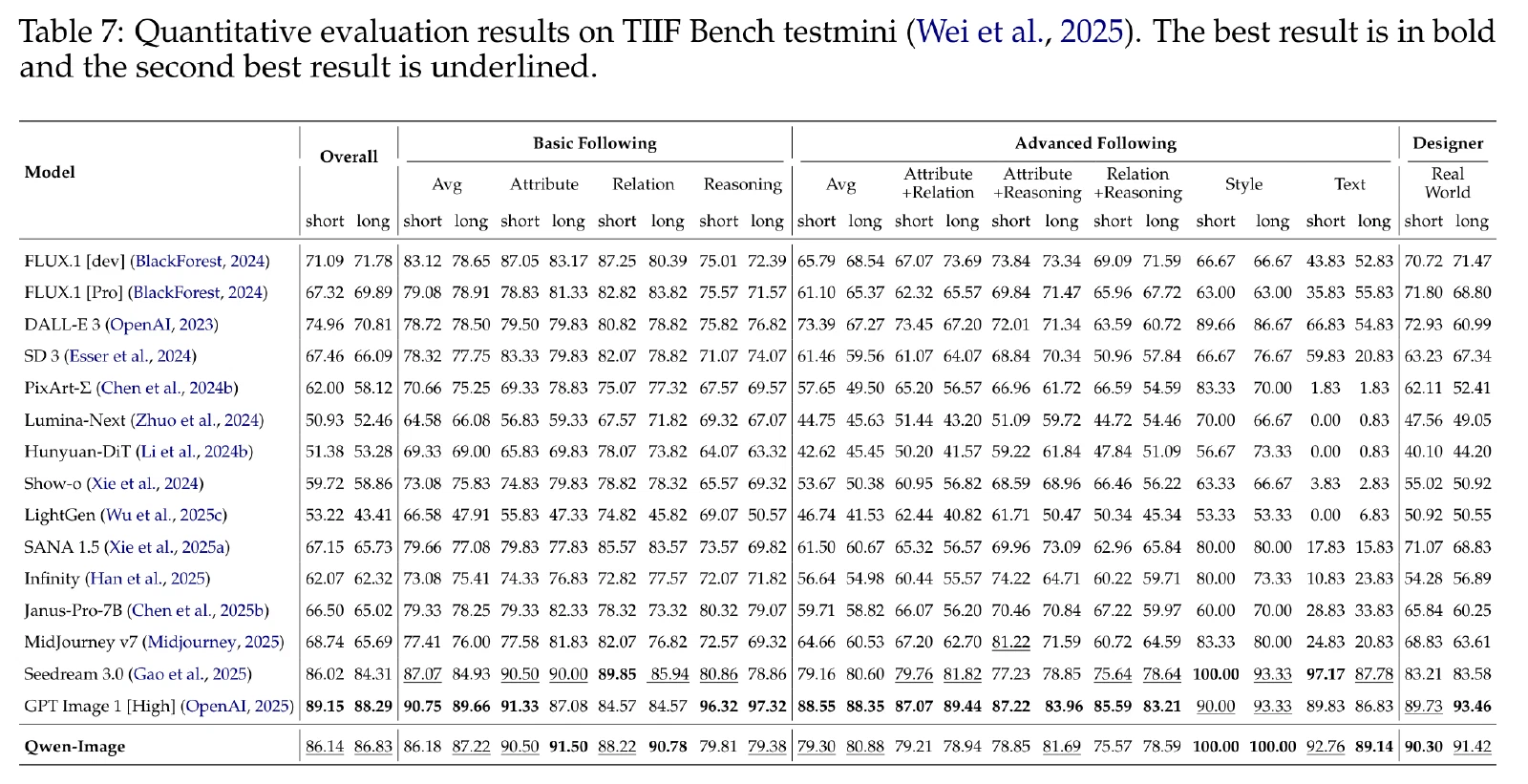
 GenEval:该基准侧重于使用具有不同对象属性的组合提示来生成以对象为中心的文本到图像。
GenEval:该基准侧重于使用具有不同对象属性的组合提示来生成以对象为中心的文本到图像。
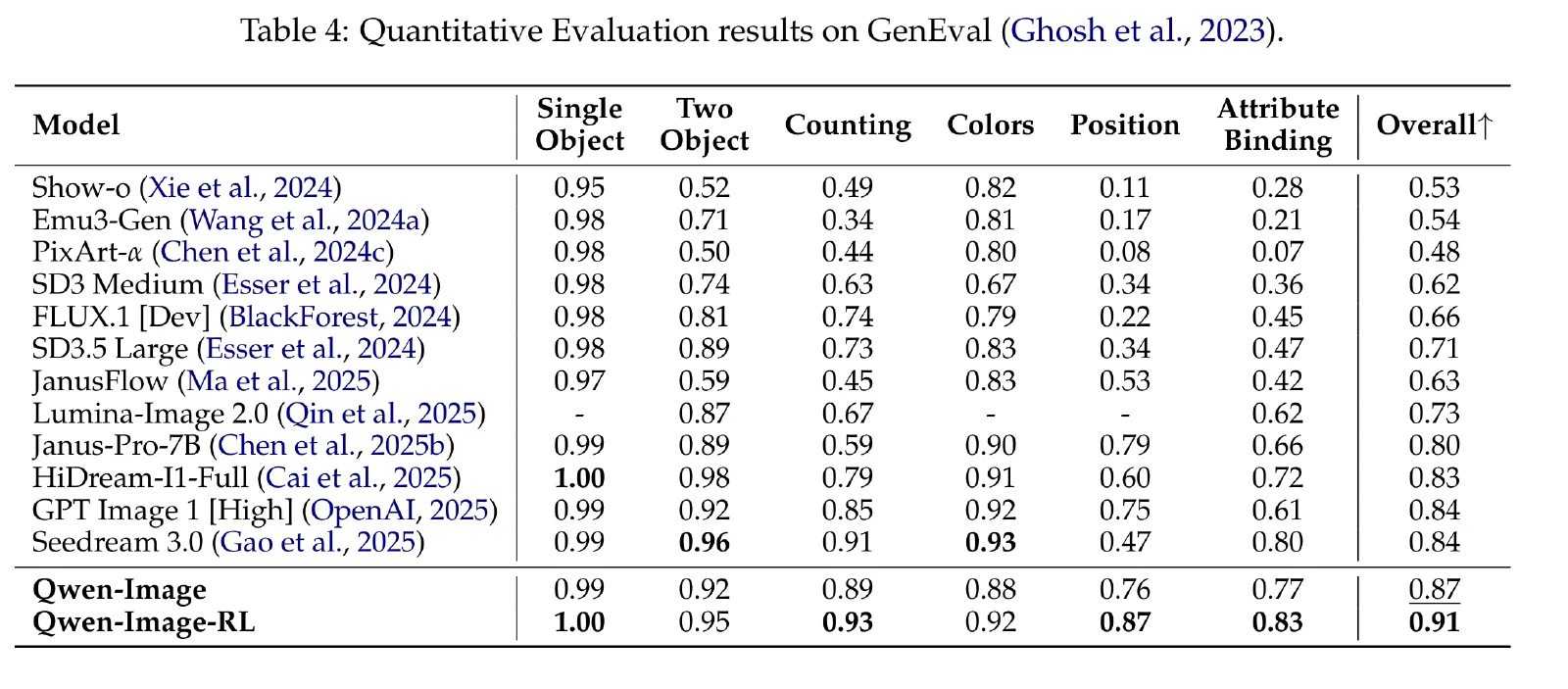
OneIG-Bench:跨多个维度对 T2I 模型进行细粒度评估而设计的综合基准。
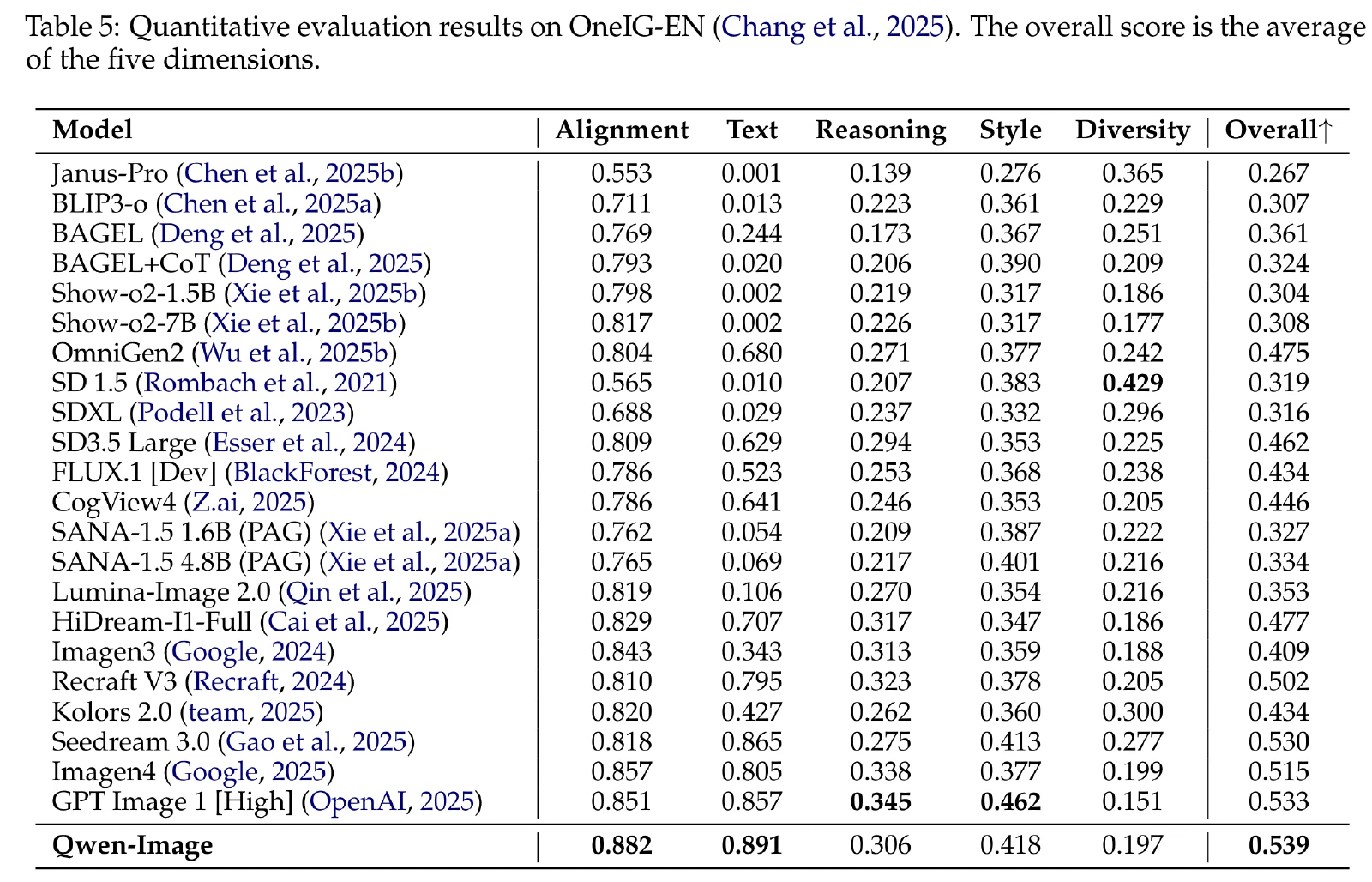
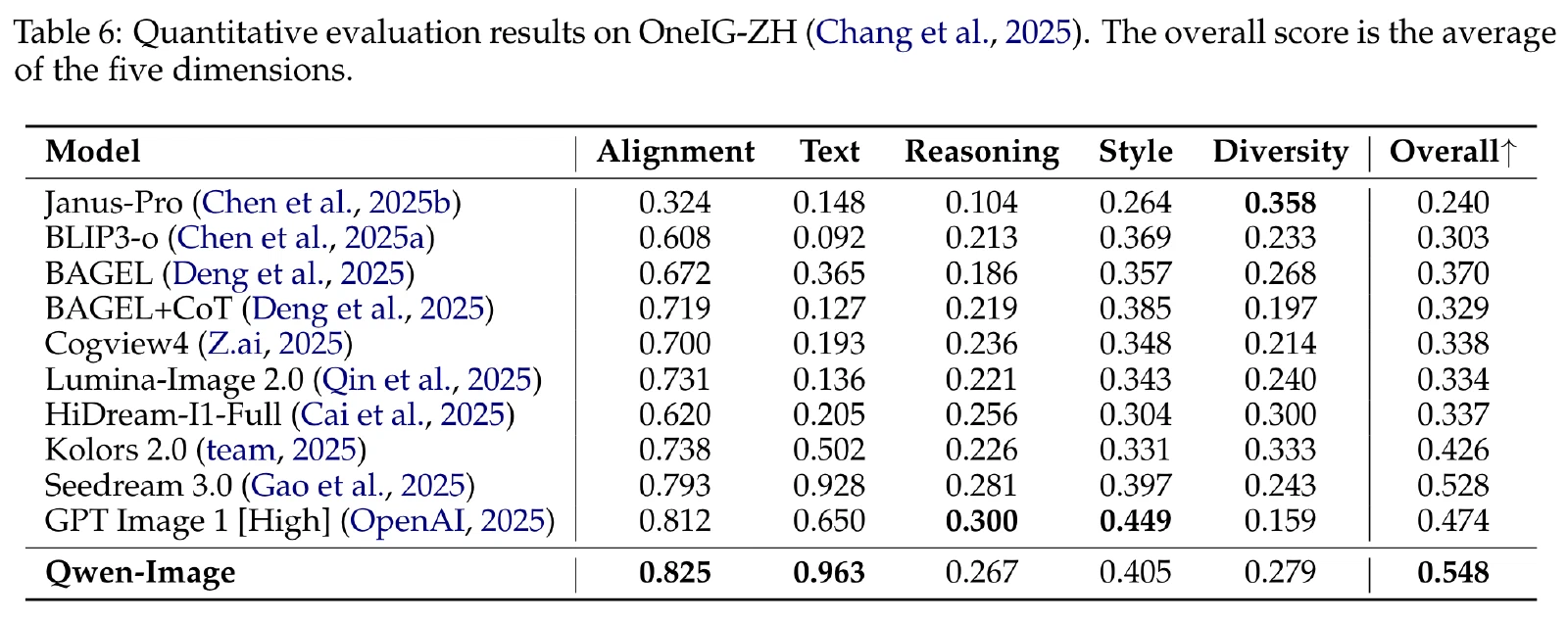
TIIF:在系统评估 T2I 模型解释和遵循复杂文本指令的能力的基准。
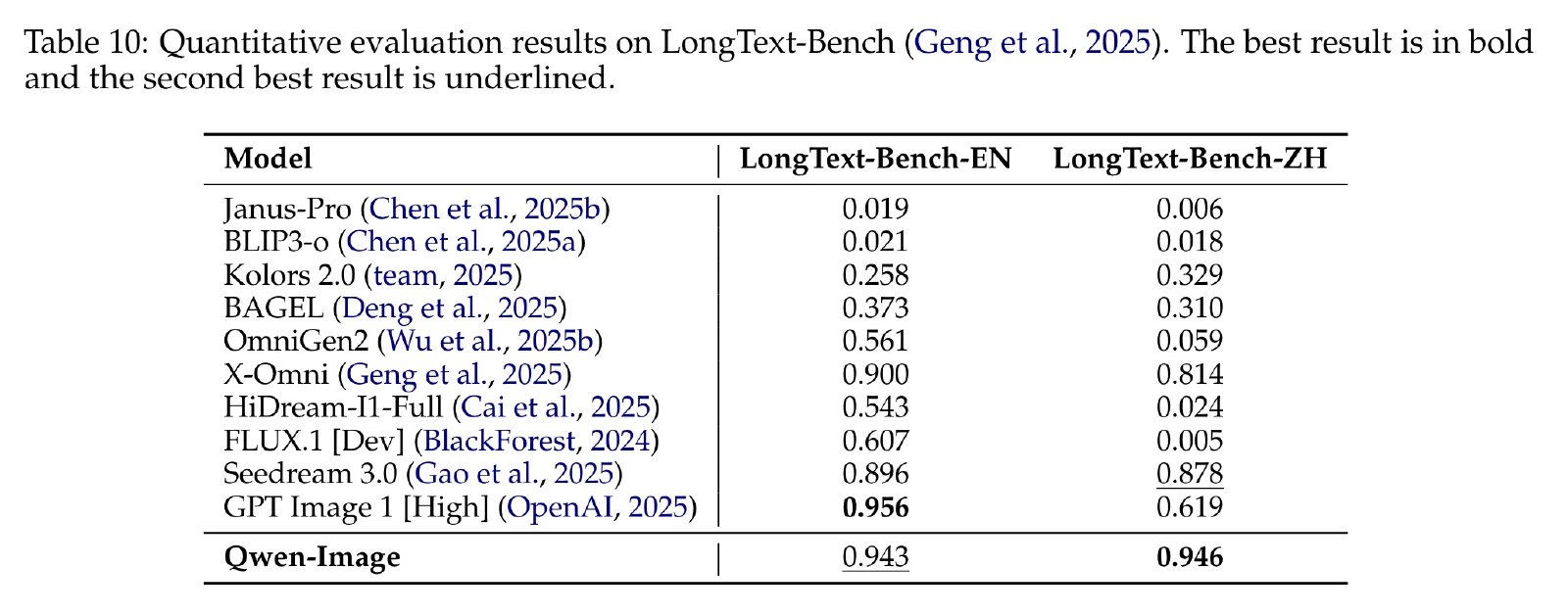
CVTG-2K:该基准测试包含 2K 提示,每个提示需要在生成的图像上渲染 2-5 个英语区域。
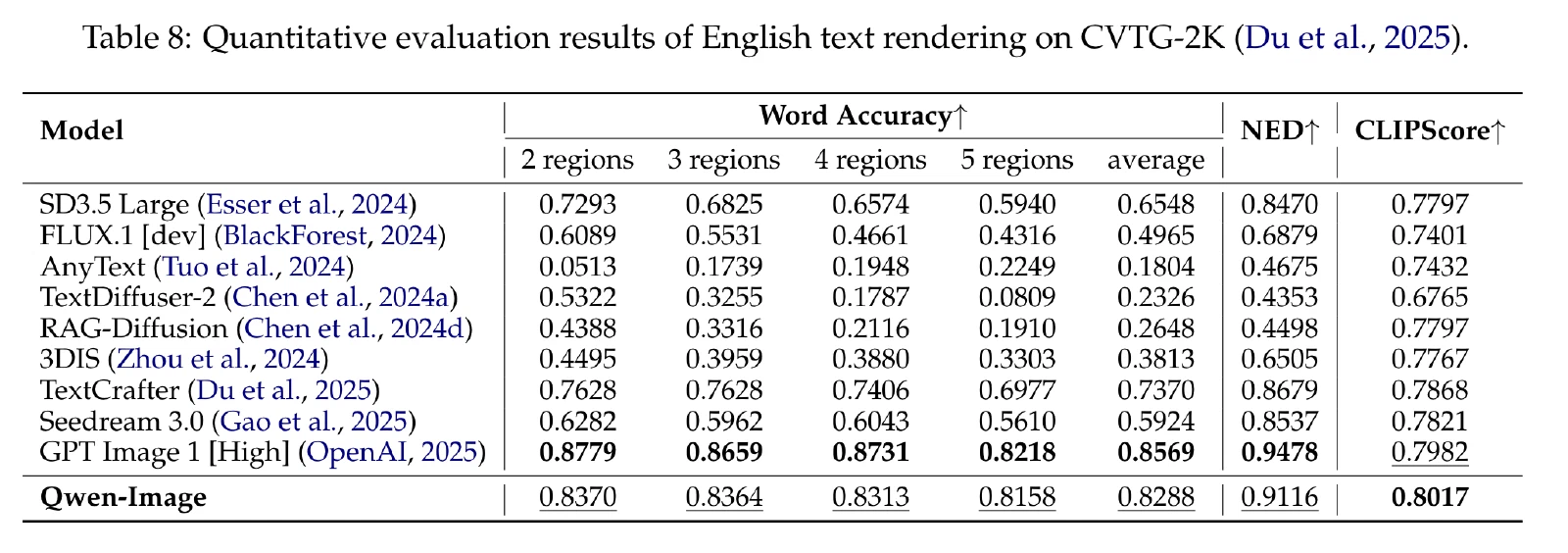
ChineseWord:本问题提出的基准。根据常用规范汉字表,我们将汉字分为三个难度等级:一级(3500字)、二级(3000字)、三级(1605字)。我们制作了几个提示模板,指示文本到图像模型生成包含单个汉字的图像。
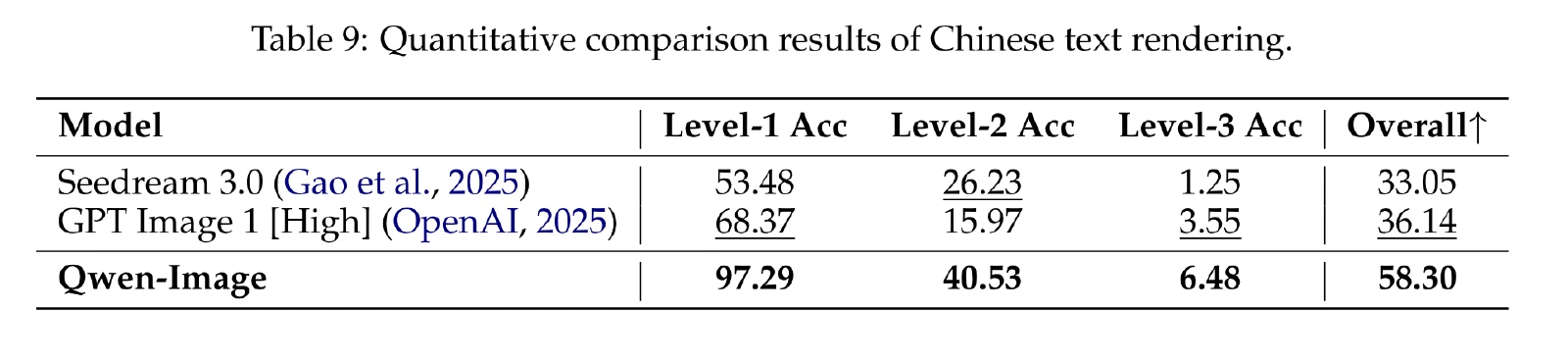
LongText-Bench:这是一个专门为评估模型精确渲染长文本的能力而设计的基准。该数据集包含 160 个提示,涵盖八个不同的场景。
图像编辑
Benchmark有:GEdit-Bench、ImgEdit、Novel view synthesis、Depth Estimation
总之效果不错。
定性指标
VAE重建效果:可以看到细节非常好,不会出现糊,仍然可以辨认。

图像生成:从英文文本渲染、中文文本渲染、多对象生成、空间关系生成四个方面进行定性评价。
- 能够渲染长段英文文本,文本保真度高。
- 精确生成中文对联,渲染结构化段落和手写文本,保持排版美观
- 精确生成指定动物及其位置,忠实呈现毛绒样式
- 准确生成符合提示的场景与对象交互,能理解并执行复杂空间和动作提示。
图像编辑:针对文本和素材编辑、对象添加/删除/替换、姿势操纵、链式编辑和新颖视图合成五个关键方面进行了定性评估。总之效果不错。
结论
Qwen-Image 是 Qwen 系列推出的一款全新图像生成基础模型,它在复杂文本渲染和精细图像编辑上表现尤为出色。通过完整的数据管道和渐进式训练策略,Qwen-Image 能在生成图像中准确呈现长文本内容,避免文字丢失、错误或重复。
相比传统图像生成模型,它不仅追求视觉美观,更强调 文本与图像的精准对齐。这意味着未来的交互界面可以从纯语言交互(LUI)升级为视觉-语言交互(VLUI),用户不仅能用文字表达意图,还能生成富含文字、结构清晰的图像。
除了文本渲染,Qwen-Image 还能处理 传统理解任务,比如深度估计。与传统判别模型不同,它通过生成理解方式构建视觉内容分布,从而自然推断深度,实现了理解与生成的结合。
更令人惊喜的是,Qwen-Image 在 3D、视频和多对象场景中也表现出色。它能保证多视角一致性,准确保留主体身份和背景结构,甚至在复杂动作或布局中保持高连贯性。
总的来说,Qwen-Image 不只是一个图像生成模型,它标志着 多模态 AI 的新方向:
- 生成模型不仅生成图像,还能理解图像
- 理解模型通过生成过程实现更深入的认知
- 视觉与语言的结合将带来更直观、智能的交互体验
核心贡献总结
- MSRoPE 多尺度旋转位置编码:将文本 token 提升为二维,沿对角线与图像位置编码统一,实现精确的图文位置对齐,是复杂文字渲染的关键支撑。
- 双流 MMDiT 架构:结合 Qwen2.5-VL 视觉编码器和 Flow Matching 训练目标,在统一框架中支持文生图、图生图和图像编辑。
- 四阶段渐进式预训练:从 256px 到 1024px+,逐步集成文字渲染能力,辅以精细的数据构建,确保生成质量。
- 两阶段后训练(SFT → DPO + GRPO):离线偏好对齐 + 在线策略优化的组合,系统性提升美学质量、文字渲染精度和编辑一致性。