论文链接:arXiv:2605.22344
Q:既然 MLLM 已经很擅长理解图像和视频,扩散模型也已经很会生成图像和视频,那能不能发挥这两个的长处,结合一下呢?
A:可以,但关键在于找到一个合适的中间表示。这个中间表示既要让 MLLM 说得明白,也要让 DiT 用得上。论文选择的是 MLLM 的 ViT embedding space。
Bernini 让 MLLM 在 ViT embedding 空间里先做语义规划,再让 DiT 在 VAE latent 空间里完成像素渲染。
生成到底该怎么做
MLLM(多模态大语言模型)和扩散模型各自已经达到了很高的成熟度,但它们的演进路径相对独立。Bernini的核心洞察是将两者统一起来,通过清晰的分工协作:
- MLLM负责语义规划(Semantic Planning):利用其强大的多模态理解能力,在ViT embedding空间预测目标内容的语义表示
- DiT负责像素渲染(Pixel Rendering):基于语义表示和低级视觉特征,通过流匹配(Flow Matching)生成高保真图像/视频
两者之间的接口使用 MLLM 自身的 ViT embedding 空间。MLLM 原本就是在这个空间里接收、理解和组织视觉信息的,所以让它在这里预测“目标画面应该长什么样”,比要求它直接吐出像素或 VAE latent 更自然。
可以把 Bernini 理解成两步:Planner、Renderer。前者要求理解和规划,后者要求保真和时序一致。
为什么使用 ViT embedding 空间?
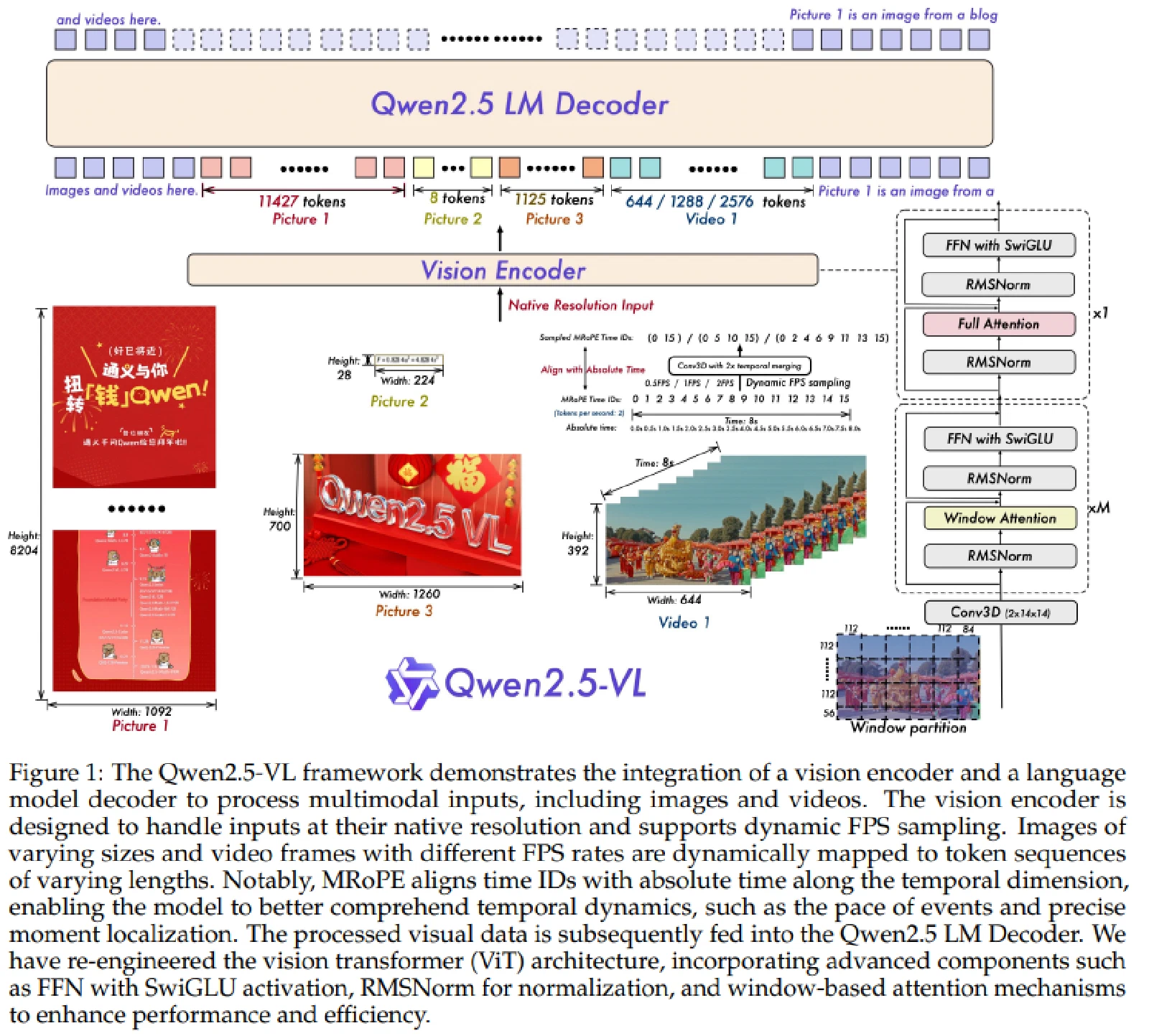
可以从 MLLM 的结构讲起。以 Qwen2.5-VL 为例,图像或视频首先经过 Vision Encoder,被编码为 Visual Tokens;这些 Visual Tokens 与文本 tokens 一起输入 Qwen2.5 LM Decoder,最终由语言模型头输出文字 token。也就是说,MLLM 并不是直接在像素空间中理解图像,而是在 Vision Encoder 输出的 ViT embedding 空间中接收和表征视觉信息。因此,用这个空间进行推理和表示,是在顺着模型原本的能力走。
这篇论文主要解决什么
读这篇论文时,可以先把问题拆成四个层次:
- 理解与生成的割裂:MLLMs 擅长语义推理,但无法直接生成像素;扩散模型擅长合成,但对复杂指令和多模态上下文的理解能力不够。
- 视频编辑任务太杂:添加、移除、替换、风格迁移、运动修改都算编辑,但每个任务过去往往有一套专门方法,很难统一。
- 多视觉输入容易混淆:参考图像、源视频、目标输出被拼进同一个序列后,可能共享相同的时空坐标,模型会分不清参考物体和目标画面。
- 高质量编辑数据少:视频编辑数据比图像编辑数据难构造得多,尤其是大规模、高质量、多任务的数据。
整体架构
Bernini 的结构由两个核心组件构成:
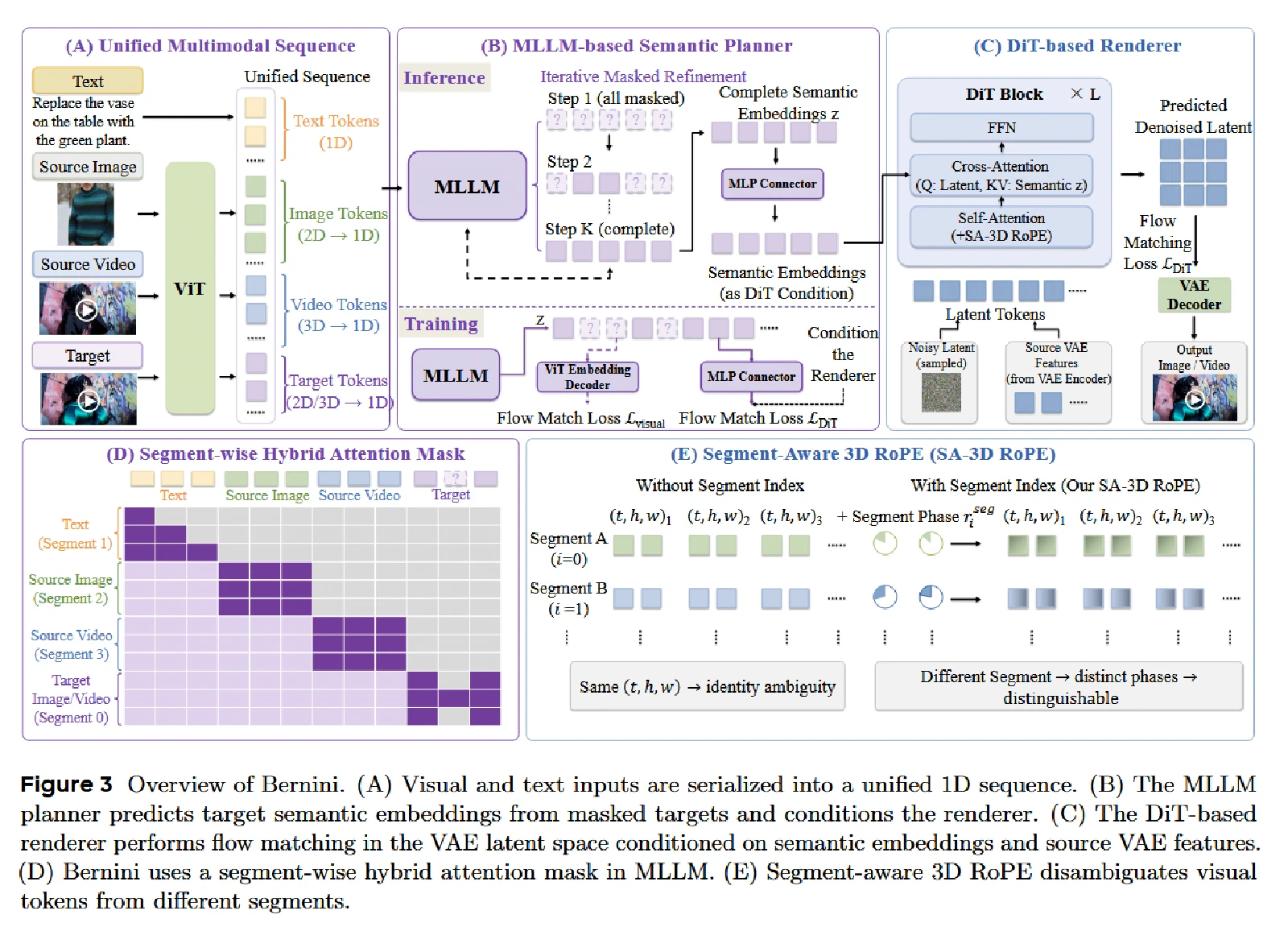
第一部分是 MLLM-based Planner。它读入文本、源图像、源视频、参考图像等上下文,然后在 ViT embedding 空间里预测目标视觉语义表示。
第二部分是 DiT-based Renderer。它拿到 Planner 给出的目标语义表示,再结合文本特征和源视频的低级视觉特征,最终在 VAE latent 空间里生成视频。
训练时,Bernini 采用联合目标,同时优化 MLLM、ViT Embedding Decoder 以及 DiT Renderer:
其中:
- $L_{ntp}$:标准 Next-Token Prediction Loss,用于保持 MLLM 的语言理解与多模态推理能力;
- $L_{visual}$:ViT embedding 空间中的 Flow Matching Loss,用于训练 Semantic Planner 预测目标视觉语义表示;
- $L_{dit}$:VAE latent 空间中的 Flow Matching Loss,用于训练 DiT Renderer 完成视频生成与编辑;
- $\lambda_{text}$、$\lambda_{visual}$、$\lambda_{dit}$ 为对应损失项的权重系数。
因此,Bernini 同时学习三件事:
- 保留 MLLM 的理解能力;
- 在 ViT embedding 空间中规划目标视觉语义;
- 在 VAE latent 空间中渲染最终视频。
MLLM-based Planner(语义规划器)
Planner采用 Qwen2.5-VL-7B 作为基础,把文本、源图像、源视频以及目标图像/视频统一序列化为一维 token 序列:
$$ z = \text{MLLM}(t, v^{src}_1, v^{src}_2, ..., v^{src}_N, v^{tgt}) $$其中,$t$ 表示文本嵌入,$v^{src}_i$ 表示第 $i$ 个源视觉输入的 ViT embedding,$v^{tgt}$ 表示目标图像/视频对应的视觉 token 序列。
这里有一个很像 masked modeling 的设计:训练时,$v^{tgt}$ 来自真实目标输出的 ViT embedding,并随机遮挡其中一部分;推理时,由于目标输出未知,所有目标视觉 token 都初始化为共享的 mask token。MLLM 对整个多模态序列编码后得到 hidden states,其中目标 token 位置上的 hidden states 就被视为目标视觉内容的语义表示。具体细节如下:
训练阶段
- 随机 mask 一部分目标视觉 token,并将其替换为共享的 mask token;
- mask 比例从 Beta 分布中采样: $$ r \sim \text{Beta}(\alpha, \beta) $$
- MLLM 根据文本、源图像、源视频以及目标序列中未被 mask 的视觉 token,推断被 mask 位置的目标视觉内容;
- 被 mask 位置对应的 hidden states 会送入 ViT Embedding Decoder,该解码器由 MLP 和 ResNet-based prediction head 组成;
- ViT Embedding Decoder 负责预测对应位置的 ground-truth ViT embeddings,并在 ViT embedding space 中使用 Flow Matching 目标进行训练。
推理阶段
- 所有目标视觉 token 首先被初始化为 mask token,然后通过 $K$ 步迭代逐步补全。第 $k$ 步的 mask ratio 按余弦调度递减: $$ \text{mask\_ratio}(k, K) = \cos\left(\frac{\pi}{2} \cdot \frac{k+1}{K}\right) $$
- 每一步中,当前预测出的目标视觉 token 会被重新送回 MLLM,作为下一轮推断的部分观测,最终从粗到细得到完整的目标 ViT embedding 序列。
DiT-based Renderer(像素渲染器)
Renderer 才是真正负责生成像素的部分。它采用 Wan2.2-A14B 作为基础,在 VAE latent 空间中进行 Flow Matching 去噪:
- 以MLLM输出的语义嵌入作为cross-attention条件
- 额外注入文本特征(T5编码器)和源VAE特征(用于编辑时的细节保留)
- 通过多条件引导的Classifier-Free Guidance合成最终输出
训练技术
SA-3D RoPE(Segment-Aware 3D Rotary Positional Embedding)
当多个视觉输入拼接为统一序列时,会出现一个很实际的问题:不同 segment 的 token 可能具有相同的 $(t, h, w)$ 时空坐标。比如参考图和目标视频的某些位置坐标相同,但语义身份完全不同。模型如果只看标准 3D RoPE,就可能发生身份混淆(identity ambiguity)。
SA-3D RoPE为每个视觉segment分配一个索引 $i$(目标segment为 $i=0$,输入segment为 $i=1,2,…$),并在标准3D RoPE的基础上引入segment依赖的全局相位调制:
$$\tilde{r}_{t,h,w,i} = r_{t,h,w} \odot r^{seg}_i$$其中 $\odot$ 表示复数逐元素乘法。这使得注意力机制能在保留3D RoPE时空建模能力的同时,区分来自不同segment的token。
直观上,SA-3D RoPE 给每段视觉输入加了一个“段身份”。消融实验表明,相比标准 3D RoPE 和添加可学习 segment embedding 的基线,它能更有效地减少参考图像外观细节泄漏到目标区域的问题(reference leakage)。
SA-3D RoPE 解决的问题是多个视觉输入放在同一个序列里时,模型怎么知道每个 token 属于哪个视觉来源。这是统一多输入视频编辑里很容易被忽略的问题。
Chain-of-Thought 推理增强
为了增强MLLM的理解能力向生成能力的迁移,引入两种CoT推理模式:
- Self-text Reasoning(自文本推理):将原始编辑指令重写为更详细、结构化、语义更丰富的编辑指令。构建了约100万样本的大规模文本CoT数据。
- Self-vision-text Reasoning(自视觉-文本推理):将视频编辑分解为两个阶段:
- 图像级推理:在首帧上进行图像编辑,产生编辑后的中间帧作为视觉中间表示
- 视频级生成:基于中间帧将编辑传播到完整视频,保持时间一致性
消融实验显示,结合文本推理和视觉-文本推理能达到最佳性能,多模态推理在纯文本推理之外提供了互补收益。
数据构建
Bernini 的训练数据是整篇论文里非常重的一部分。原因也很简单:模型想统一处理 T2V、I2V、V2V、参考图驱动生成、视频编辑等任务,就不能只靠单一数据源。它的训练语料覆盖文本理解、图像/视频生成、图像/视频编辑等多种任务。
预训练数据
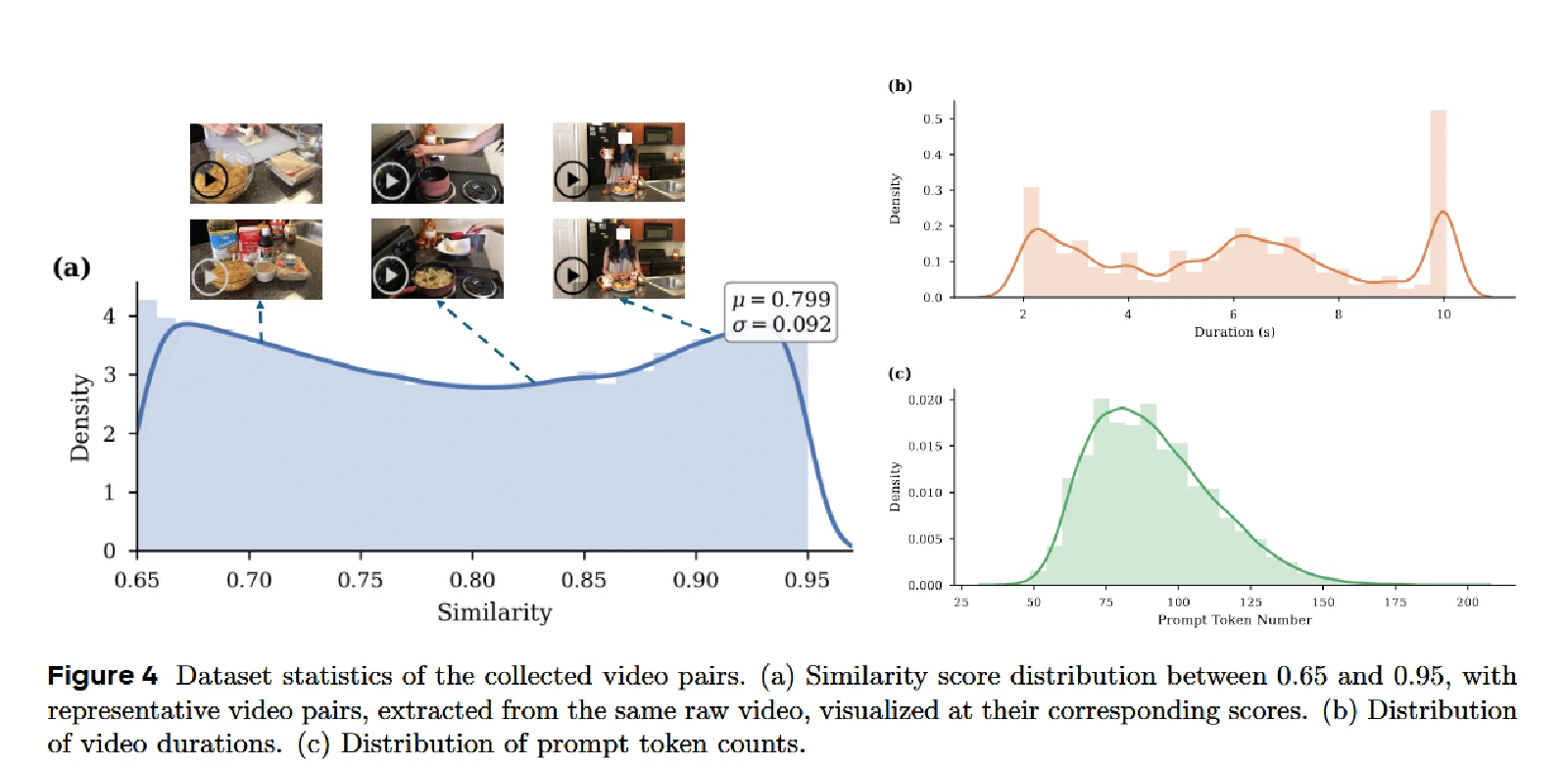
Video-pair数据(2000万对):
- 从通用T2V语料中,对同源视频的片段计算X-CLIP相似度
- 筛选相似度在 $[0.65, 0.95]$ 之间、时长2-10秒的片段对
- 1:1平衡人物/非人物内容(由Qwen3-VL-30B标注)
- 使用Qwen3-VL-235B进行coarse-to-fine指令生成

Image-pair数据(近3000万对):
- 从30万+教程视频中提取关键帧
- 通过CLIP相似度筛选 $[0.75, 0.95]$ 的图像对
- 使用Qwen3-VL生成描述视觉差异的文本提示

Interleaved Image-text数据(约1000万):
- 网页数据:从OmniCorpus构建,Qwen3-32B重生成文本以提升流畅度
- 视频数据:从T2V语料提取最多8个关键帧,生成帧间文本过渡描述
图像编辑和图像到视频编辑数据
Bernini 做了一个转换:把一部分视频编辑问题先重构为图像到视频编辑问题。
先利用强图像编辑模型获得高质量的编辑后首帧,再通过图像到视频生成将图像级编辑能力迁移到视频生成中,最终服务于视频到视频编辑训练。
具体而言,作者首先构造图像编辑三元组,即 $(\text{Source Image}, \text{Edited Image}, \text{Edit Prompt})$。编辑指令由两种互补方式生成: 在获得编辑后图像之后,作者进一步使用 MLLM 生成对应的 motion prompt,将静态图像编辑扩展为图像到视频编辑数据。最终得到两类训练样本:一类是图像编辑三元组 $(\text{Source Image}, \text{Edited Image}, \text{Edit Prompt})$,用于学习图像级编辑能力;另一类是图像到视频三元组 $(\text{Source Image}, \text{Video}, \text{Edit Prompt}+\text{Motion Prompt})$,用于将编辑后的静态视觉状态扩展为动态视频。这部分数据的作用是把成熟的图像编辑监督迁移到视频生成中,从而提高视频编辑任务的多样性和泛化能力。点击展开

Propagation-based数据增强:
最开始文章使用DiffuEraser和VACE生成addition/removal/replacement数据,但存在伪影和多样性不足。因此做了如下改进:
- 训练基础propagation模型,将源视频 + 编辑后的首帧 + 编辑指令 → 目标编辑视频
- 结合强图像编辑模型生成高质量首帧,从而提升整体视频编辑质量
强图像编辑模型更容易生成高质量的编辑后首帧,而 propagation model 负责将首帧中的编辑结果传播到后续帧,并尽量保持时间一致性。这样,视频编辑数据的构造被拆解为两个相对更容易的问题:首先生成高质量 edited first frame,然后将该编辑状态沿时间维度传播为完整视频。相比直接用现有视频编辑模型生成整段视频,这种方式可以显著降低伪影,提高编辑质量和任务覆盖范围.
此外,对 addition、removal 和 replacement 等任务进行源视频与编辑视频的交换,并使用 MLLM 重新生成匹配的反向编辑 prompt。

Motion-aware数据(人机交互场景):
- 提出双分支融合框架:
- I2V分支:引入动作适应性,允许编辑后的人体姿态自然变化
- V2V分支:保持源视频运动一致性
- 通过加权引导融合两个分支的输出
Reference-image-guided Video Generation and Editing Data
Reference-to-Video(R2V):
- 通用物体R2V:MLLM识别视频中3-5个最显著物体,为每个物体编写编辑指令,提取对象并放到不同的场景中,生成(reference, keyframe)的R2V标注。
- 人物R2V:利用长视频中的身份重现,从同一视频/剧集中检索同身份参考片段
Reference+Video-to-Video(RV2V):
- 使用中间版本视频编辑器,为R2V样本生成移除/替换参考物体的指令,产生输入视频
Reference-video-guided Video Generation Data
Motion Transfer(动作迁移):
- 从真实视频中提取DWPose,用Bernini的pose-to-video能力生成参考视频
- 参考图像从目标视频中随机采样一帧

Reasoning-augmented Video Data
受 Emu3、OmniGen2等统一模型的启发,Bernini 也把显式思维链纳入到视频编辑训练中。不过这里的 Chain-of-Thought 不是推理阶段让模型显式输出一段长文本推理,而是作为训练阶段的额外监督信号注入到 Planner 中。
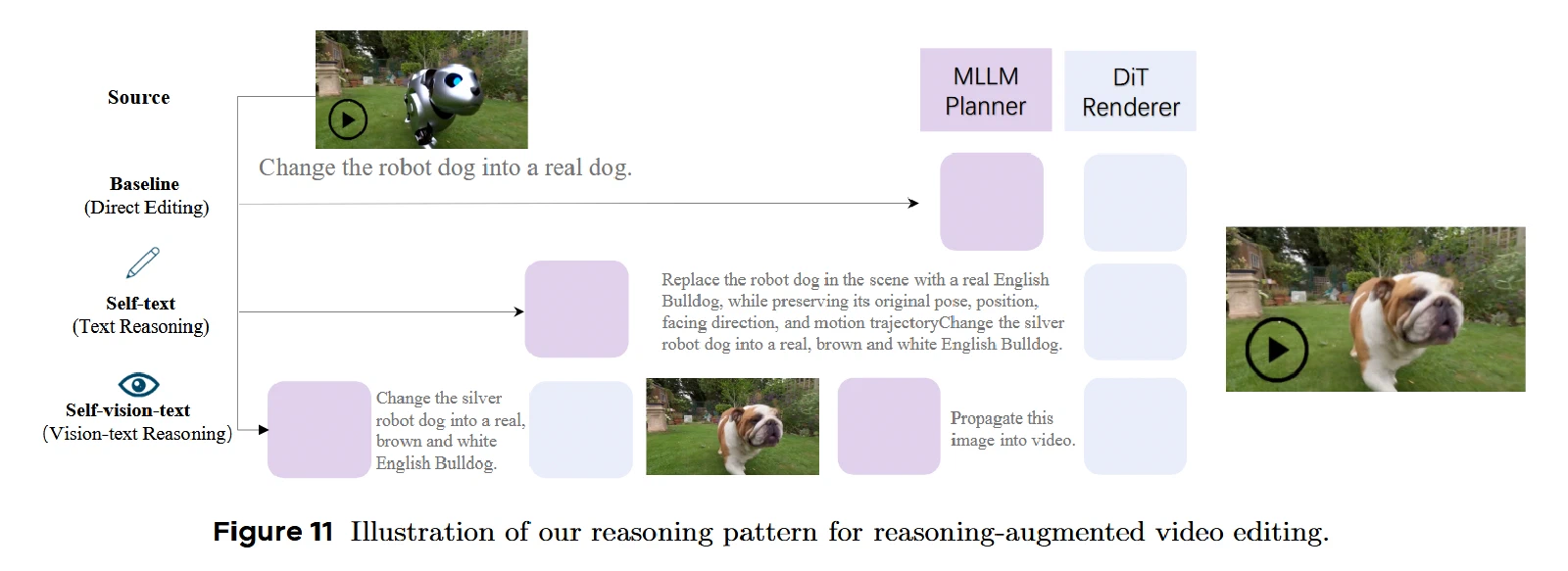
Self-text Reasoning:将原始编辑指令扩展为更详细的结构化编辑计划,为MLLM提供显式语言推理路径。
Self-vision-text Reasoning:进一步引入编辑后首帧作为视觉中间状态,将视频编辑分解为“图像级编辑→视频级传播”两个阶段,从而在视觉空间中构建隐式推理链。
三阶段训练策略
前面讲了模型和数据,接下来是训练策略。Bernini 没有一上来就端到端训练所有模块,而是分三步逐渐对齐:先让 Planner 学会做视觉语义规划,再让 Renderer 学会高质量渲染,最后再做联合训练。
| Stage | Optimized | Res. | LR | EMA | T2I | T2V | I2I | V2V | I2V | IV2V | V.P. | I.P. | Int. | Und. | CoT |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I | MLLM | 256p | 1e-5 | 0.999 | 13% | 19% | 3% | 1% | 1% | 1% | 15% | 21% | 6% | 20% | — |
| II | DiT | 480p | 1e-5 | 0.9995 | 31% | 42% | 4% | 0.4% | 0.4% | 0.3% | 11% | 11% | — | — | — |
| II | DiT | 480p | 1e-5 | 0.9999 | 20% | 30% | 40% | 3.3% | 3.5% | 3.2% | — | — | — | — | — |
| III | All | 480p | 1e-5 | 0.9995 | 16% | 24% | 32% | 2.6% | 2.8% | 2.6% | — | — | — | 20% | — |
| III | All | 480p | 1e-5 | 0.999 | 12% | 18% | 24% | 2% | 2% | 2% | — | — | — | 20% | 20% |
其中的
- Res. = Resolution
- V.P. = Video Pairs
- I.P. = Image Pairs
- Int. = Interleaved Image-Text Data
- Und. = Understanding Data
- CoT = Reasoning-augmented Video Data
对应的来说,可以看下表:
| Stage | 优化模块 | 分辨率 | 主要目标 | 核心数据 |
|---|---|---|---|---|
| I | MLLM Planner | 256p | 将Qwen2.5-VL从理解模型转化为语义规划器 | Understanding、Image Pair、Video Pair、多任务生成编辑数据 |
| II | DiT Renderer | 480p | 学习高保真生成与编辑能力 | T2I/T2V预训练 + I2I/I2V/V2V/IV2V编辑数据 |
| III | 全模型联合训练 | 480p | 对齐语义规划与视频渲染,并引入推理能力 | 高质量生成编辑数据 + Understanding Data + CoT Data |
Stage I:MLLM预训练
- 目标:将Qwen2.5-VL从多模态理解模型转化为语义规划器,并学习在ViT embedding空间预测目标视觉语义表示
- 损失:$\lambda_{text}L_{ntp} + \lambda_{visual}L_{visual}$,其中 $\lambda_{text}=0.2, \lambda_{visual}=1$
- $L_{ntp}$ 用于保持MLLM原有的语言与多模态理解能力
- $L_{visual}$ 用于训练ViT Embedding Decoder恢复目标ViT embedding
- 渐进式数据课程:先T2I建立图像生成能力,再扩展到T2V、I2I、V2V,为了提高跨异构任务的鲁棒性,我们采用了任务相关的掩码比率策略。mask 比例从 Beta 分布中采样: $r \sim \text{Beta}(\alpha, \beta)$,不同任务的信息量不同,训练时采用任务相关的mask比例策略:
| 任务 | $\alpha$ | $\beta$ |
|---|---|---|
| T2I | 5.0 | 1.1 |
| T2V | 8.0 | 1.05 |
| I2I | 8.0 | 1.05 |
| I2V | 10.0 | 1.0 |
| V2V | 12.0 | 0.9 |
| IV2V | 12.0 | 0.9 |
随着任务输入信息量的增加(从纯文本生成到图像/视频条件编辑),分布向概率1.0偏移,即更多目标token被mask,迫使规划器从高层多模态上下文中推断语义,减少信息泄漏。
Stage II:DiT预训练
- 目标:赋予渲染器高保真合成和源保持编辑能力
- 损失:$L_{dit}$,条件为文本特征和源VAE特征
- Pair数据采样比例线性衰减:初期高比例以提升泛化,后期降至零以精调编辑性能
- 不同任务采用定制的shift参数和噪声加权方案(logit-normal/mode分布)
| Parameter | T2I | I2I | T2V | I2V | V2V | IV2V |
|---|---|---|---|---|---|---|
| Weighting | logit-normal | logit-normal | mode | mode | mode | mode |
| Shift | 3.0 | 4.0 | 3.0 | 5.0 | 5.0 | 5.0 |
其中:
- Weighting 表示 Flow Matching 训练时的时间步采样权重分布。
- logit-normal:更适合图像任务(T2I、I2I),会覆盖更广泛的噪声区间。
- mode:更适合视频任务(T2V、I2V、V2V、IV2V),更加关注主要训练区域,提高视频生成稳定性。
- Shift 为 Flow Matching 中的时间重参数化系数(shift parameter)。
- 较大的 Shift(如 5.0)会使训练更加关注高信噪比区域,有利于复杂视频编辑任务。
- 较小的 Shift(如 3.0)则更加均衡地覆盖整个噪声空间。
总体上,Bernini 对图像生成和视频编辑采用了不同的 Flow Matching 训练策略:图像任务更关注全局泛化能力,而视频任务更强调时序一致性和编辑稳定性。
展开:logit-normal 和 mode sampling 是什么?
它们都是 Flow Matching 训练中的 时间步采样策略。训练时需要采样一个时间步 $t\in[0,1]$,表示当前样本的噪声程度。不同采样策略会让模型更关注不同噪声区间。图像任务主要关注单帧质量,因此使用 logit-normal 覆盖较完整的噪声区间;视频任务还要学习运动和时间一致性,因此使用 mode sampling,让训练更关注对视频生成更关键的噪声区域。
mode sampling 通过函数变换把均匀采样的 $u$ 映射成新的时间步:
$$f_{mode}(u;s) = 1-u - s\left( \cos^2\left(\frac{\pi}{2}u\right)-1+u \right)$$从而构造出更加偏向特定噪声区域的采样分布。
logit-normal sampling 来源于 Stable Diffusion 3,是一种非均匀采样方式,先在 logit 空间中采样,再映射回 $[0,1]$:
$$\pi_{ln}(t;m,s)= \frac{1}{s\sqrt{2\pi}} \frac{1}{t(1-t)} \exp\left( -\frac{(\operatorname{logit}(t)-m)^2}{2s^2} \right)$$其中:
$$\operatorname{logit}(t)=\ln\frac{t}{1-t}$$Stage III:联合训练
- 目标:对齐语义规划与视觉渲染
- 损失:$\lambda_{ntp}L_{ntp} + \lambda_{visual}L_{visual} + \lambda_{dit}L_{dit}$
- 仅轻量联合训练,保持两个组件的预训练优势
- 后期引入CoT推理增强数据,提升结构化推理能力
推理策略
推理时也可以按两阶段理解:先在 ViT embedding 空间里把目标语义补出来,再把这个语义表示交给 DiT 渲染成视频。
ViT Embedding规划
- 目标视觉token初始化为全mask
- MLLM通过25步迭代逐步预测目标语义token
- 每步预测结果通过ViT Embedding Decoder进行5步Flow Matching去噪精炼(文本引导尺度1.2,图像引导尺度1.0)
- 完整目标ViT嵌入与文本、源ViT嵌入一起重新输入MLLM,产生DiT条件
迭代规划的额外开销相对于DiT渲染几乎可忽略。
DiT渲染
为了控制不同条件对生成结果的影响,Bernini 将最终预测拆分为:
- 无条件预测(Unconditional Prediction)
- Video Guidance
- Image Guidance
- Text Guidance
- Target Semantic Guidance
采用多条件分解的Classifier-Free Guidance:
$$\hat{\epsilon} = \epsilon_{\emptyset,\emptyset,\emptyset,\emptyset} + \omega_{vid}\Delta_{vid} + \omega_{img}\Delta_{img} + \omega_{txt}\Delta_{txt} + \omega_{tgt}\Delta_{tgt}$$其中各增量项分别对应源视频VAE特征、源图像VAE特征、文本特征和目标语义嵌入的条件贡献。
不同任务的引导尺度:
| 任务 | Steps | $\omega_{txt}$ | $\omega_{vid}$ | $\omega_{img}$ | $\omega_{tgt}$ |
|---|---|---|---|---|---|
| T2V | 60 | 4.0 | — | 1.0 | 1.0 |
| S2V | 40 | 4.0 | 1.25 | 2.5 | 1.5 |
| V2V | 40 | 4.0 | 1.25 | 1.25 | 0.5 |
| RV2V | 40 | 4.0 | 1.25 | 3.0 | 1.5 |
infrastructure优化
训练优化
- 内存优化:通过 FSDP 配置优化,将单卡显存从 72GB 降至 40GB。
- 输入管线优化:将原本“先拼接再 scatter”的流程改为直接 index-scatter 到预分配 buffer,减少约 17GB 中间显存。
- 激活卸载:使用 pinned CPU memory pool + delayed-queue prefetch,实现 D2H/H2D 与计算重叠,最终支持 440K token 长序列训练,相比原 100K 提升 4.4 倍。
- 算子优化:采用 FlashAttention-4、FlexAttention、异步 QKV 通信、TND layout 保留、QuACK RMSNorm kernel 等,整体最高带来 46% 训练加速。
- 并行策略:结合 FSDP 权重切分与 Ulysses-style Sequence Parallelism;MLLM 在 SP degree=4 时吞吐提升约 2 倍。
- 序列打包与批处理:使用变长 FlashAttention、batch forward、dummy-forward padding 和 token-bucket batching,减少 padding 浪费并提高 GPU 利用率,端到端吞吐提升约 4.5 倍。
- 数据加载负载均衡:使用 greedy bin-packing 在节点间重新分配样本,使 max/min workload ratio 低于 1.01,并带来约 15% 吞吐提升。
推理优化
- DiT 推理并行:集成 DeepSpeed Ulysses,并对 QKV tensor 使用异步 all-to-all 通信。
- VAE 推理并行:沿时间维度使用 context parallelism,并采用异步卷积缓存传输。
- 整体效果:多 GPU 推理带来超过 7.2 倍加速。
模型蒸馏
- Stage 1:CFG蒸馏:学生模型直接预测CFG组合输出,单步前向替代条件/无条件双评估,每步计算减半
- Stage 2:ReFlow:拉直概率流ODE轨迹,以更少积分步实现准确生成
最终学生模型仅需4 NFE即可达到教师模型80 NFE的可比质量
实验结果
实验部分可以从两个角度看:第一,Bernini 作为视频编辑模型是否真的更强;第二,引入 MLLM Planner 之后,基础视频生成能力有没有被削弱。
看实验时重点关注两个信号:视频编辑指标是否提升,以及 T2V 基础能力是否保持。前者说明 Planner 真的带来了更好的语义控制,后者说明统一框架没有明显牺牲原本的视频生成能力。
Bernini-Bench(自建评测集)
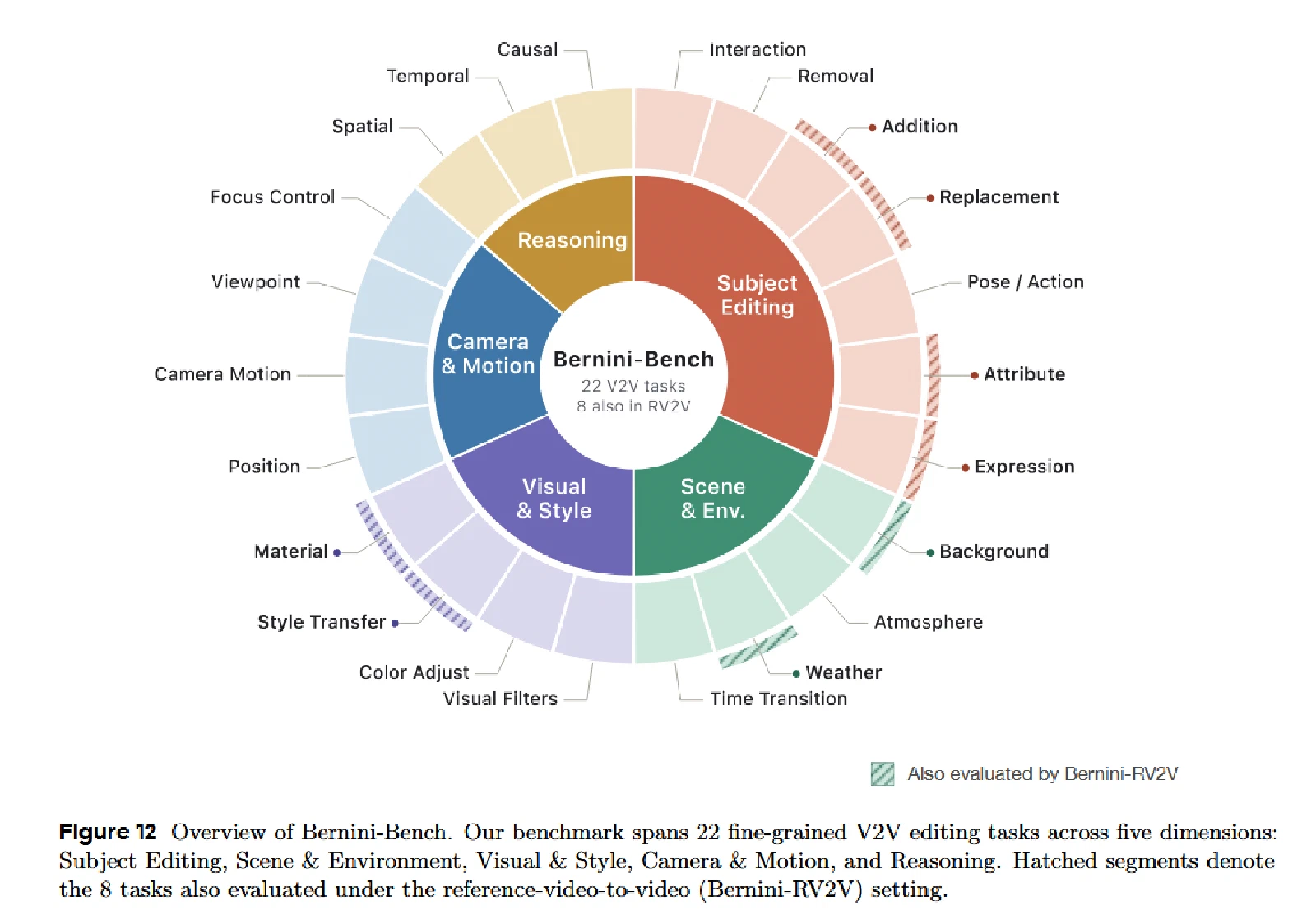
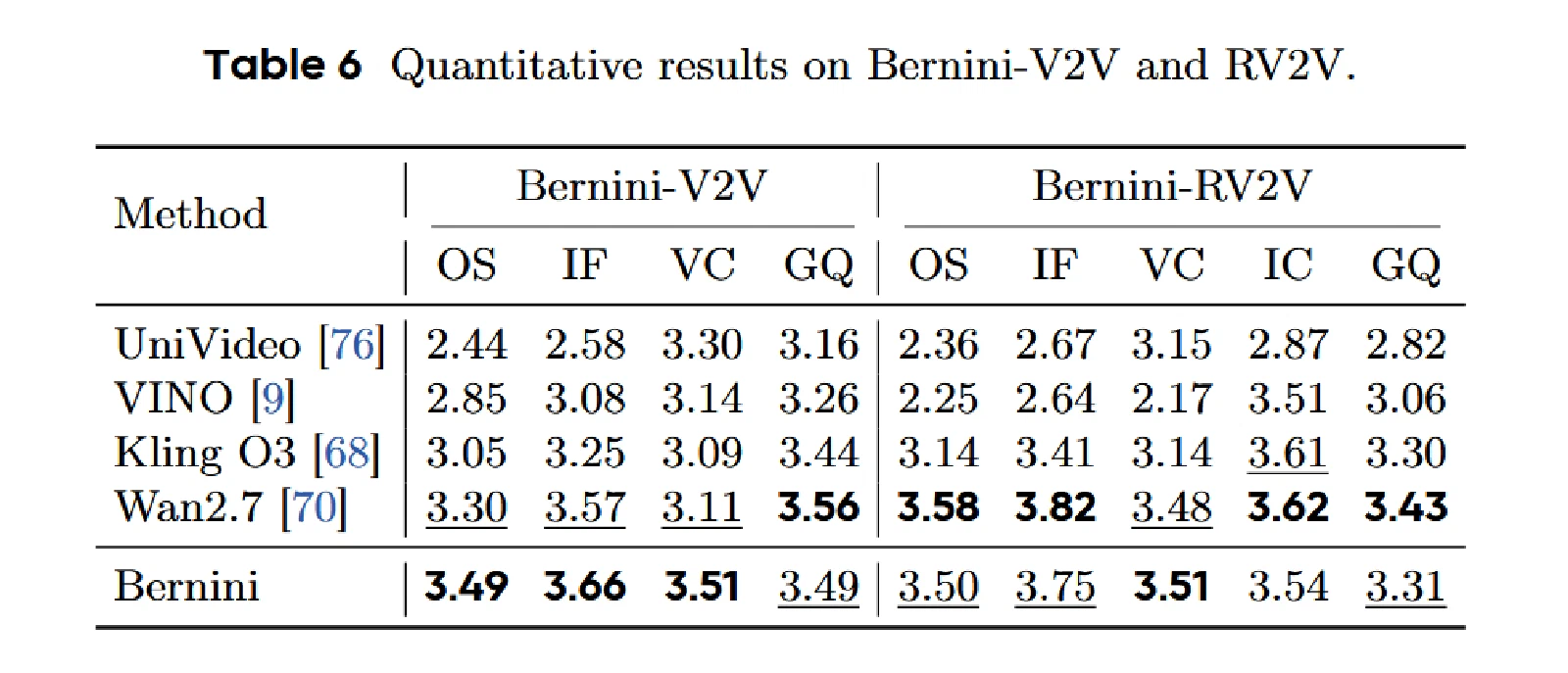
覆盖22种细粒度编辑任务、300个测试用例,支持V2V和RV2V两种设置,评估维度包括指令遵循(IF)、视频一致性(VC)、参考图像一致性(IC)、生成质量(GQ)、总体得分(OS)。
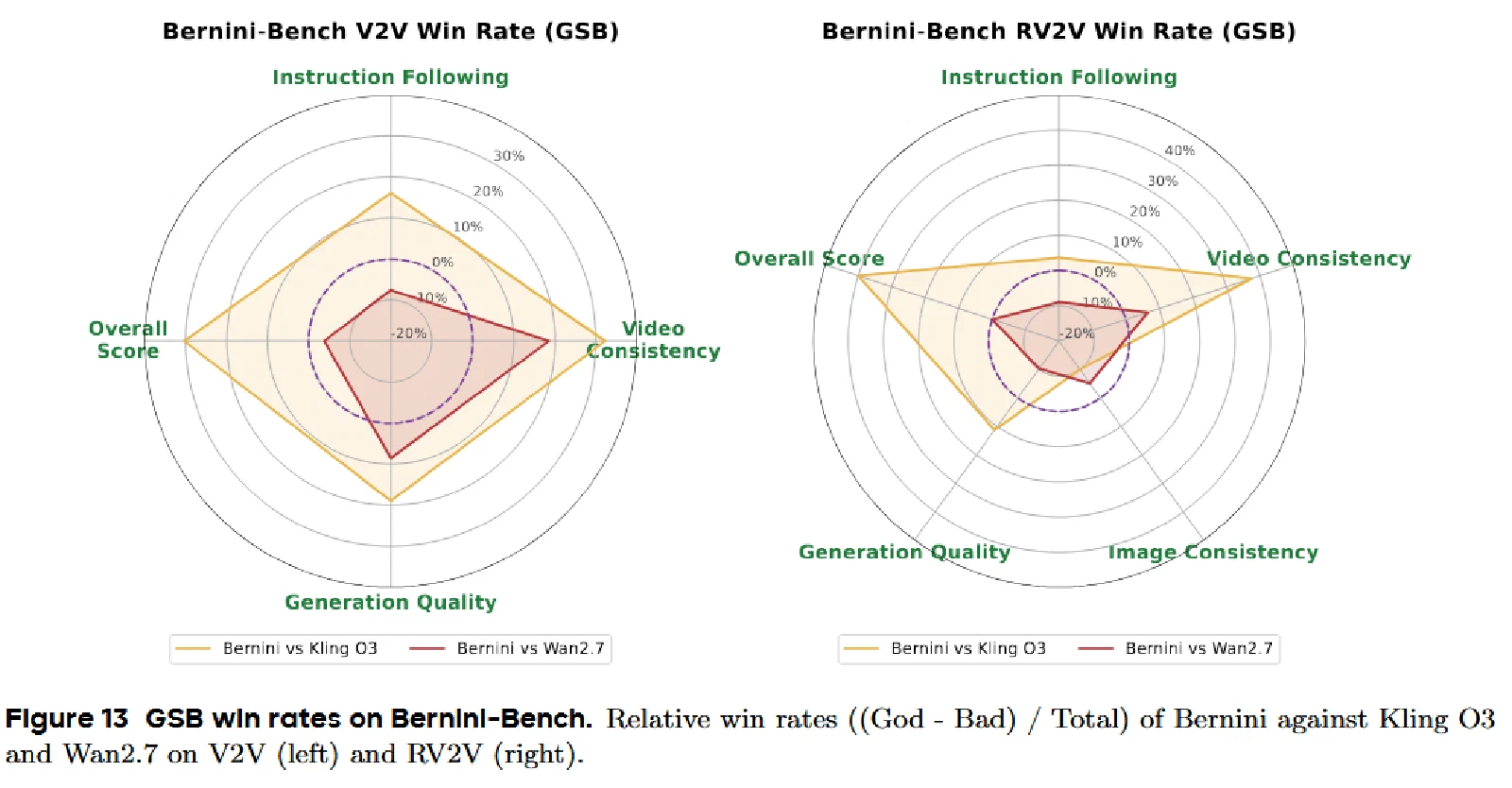
V2V结果:Bernini总体得分3.49,超越Wan2.7(3.30)和Kling O3(3.05),尤其在视频一致性上优势显著(3.51 vs 3.11)。
RV2V结果:Bernini总体得分3.50,视频一致性3.51,与Wan2.7(3.48)和Kling O3(3.14)相比均保持领先。
公开基准评测
OpenVE-Bench:总体得分 4.04,大幅超越最强基线 VINO(3.18)。
EditVerse:编辑质量8.02(新最高),Pick Score 20.26,文本对齐27.37。
FiVE:在结构保持、背景保留、文本对齐、编辑精度等指标上达到SOTA或接近SOTA,FiVE-Acc准确率78.16显著领先。
视频生成评测
VBench(T2V):Total 84.64,与Wan2.2-A14B(84.79)基本持平,说明统一框架扩展未损害基础T2V能力。
OpenS2V-Eval(Subject-to-Video):Total 62.94,超越所有开源和闭源方法。其中FaceSim高达78.20,超过次优基线Kling O3(57.20)逾20个绝对点,在多人脸身份保持上取得突破性进展。
消融实验
| 方法 | OS | IF | VC | GQ |
|---|---|---|---|---|
| Baseline | 3.12 | 3.36 | 3.18 | 3.37 |
| + PE (Qwen2.5-VL-7B) | 3.20 | 3.43 | 3.21 | 3.39 |
| + Self-text | 3.33 | 3.55 | 3.31 | 3.44 |
| + PE (GPT-5.4) | 3.49 | 3.66 | 3.51 | 3.49 |
| + PE (GPT-5.4) + Self-vision-text | 3.52 | 3.65 | 3.54 | 3.49 |
推理增强一致性地提升性能,视觉-文本推理在最强文本推理基础上进一步带来增益。
Related Work
Related Work 可以按两条路线理解:一条路线是把理解和生成放进同一个统一主干里,另一条路线是保留 MLLM 和 Diffusion Model 两个模块,再研究它们之间怎么传递条件。
统一多模态主干
这一类方法希望用一个统一 Transformer 同时处理文本、图像和视频 token。它们的核心思想是:把理解和生成都放进同一个 backbone 里完成。
代表方法包括:
- Emu3:将文本、图像、视频全部离散化到统一词表中,用 next-token prediction 训练单一 Transformer。
- Janus:保留统一自回归 backbone,但将理解和生成的视觉编码器解耦,理解侧使用 SigLIP-style encoder,生成侧使用 VQ tokenizer。
- Show-o:在同一个 Transformer 中结合文本自回归建模和图像 token 的离散扩散。
- HunyuanImage 3.0:进一步引入 MoE decoder,同时处理文本 next-token prediction 和图像 token 的 diffusion prediction。
- BAGEL:使用 Mixture-of-Transformer-Experts 架构,不同理解/生成专家通过共享 self-attention 交互。
- Lumina-DiMOO:放弃自回归预测,使用统一离散 masked diffusion 目标建模文本和视觉 token。
这类方法的优点是形式统一,缺点也很明显:训练成本高,而且理解能力和生成能力容易互相干扰。
MLLM作为生成条件
第二类方法不强行把理解和生成合并到一个 backbone,而是保留两个模块:MLLM 负责理解和提供条件,Diffusion Model 负责生成图像或视频。这类方法的差别主要在于:MLLM 到 Diffusion Model 之间传递什么表示。
代表方法:
- MetaQuery:使用少量可学习 Query Token 作为 MLLM 与扩散模型之间的桥梁。
- Bifrost-1:利用 Patch-Level CLIP Latent 作为语义接口连接 MLLM 与图像生成器。
- SEED-X:直接使用 MLLM Hidden States 作为图像生成模型的条件输入。
- DreamLLM:将 MLLM Hidden States 输入视觉解码器,实现理解与生成统一训练。
- Emu:利用 MLLM Hidden States 驱动外部图像生成器,实现多模态理解与生成协同。
- LaVi-Bridge:重点研究冻结语言模型与视觉生成模型之间的桥接机制。
- UniVideo:将 MLLM Hidden States 与视频扩散模型结合,实现统一的视频生成与编辑框架。
- VInO:结合 MLLM、VAE Latent 和视频扩散模型,统一支持 Subject-to-Video 与 Instruction-based Video Editing。
特别地,Bernini 不直接使用 MLLM 的 output hidden states 作为接口,而是将接口锚定在 MLLM 自身的 ViT embedding space。Planner 不是只提供一段语义提示,而是在视觉语义空间里规划目标输出。
局限性与总结
Bernini的最大贡献是将两者用ViT embedding进行连接:MLLM 不直接生成像素,而是负责语义规划;DiT 不负责深层推理,而是专注高保真渲染。这个分工让两个已经很强的模型各自留在更擅长的位置上。
主要贡献
本文提出了 Bernini,一种统一的视频生成与编辑框架。它的主要贡献包括:
- 提出ViT embedding空间作为语义接口,实现MLLM理解能力向生成任务的直接迁移
- 设计SA-3D RoPE解决统一序列中多视觉segment的身份混淆问题
- 引入Latent Chain-of-Thought推理增强,桥接空间推理与时间生成
- 构建大规模多任务训练语料和多样化数据合成管线,支撑统一的视频生成与编辑
- 在视频编辑、主体驱动视频生成、文本到视频生成等多个基准上达到SOTA性能
局限性
- 复杂编辑场景仍依赖外部LLM重写器提供详细结构化指令,原生推理能力尚不充分
- 主体驱动视频生成的视觉质量与更强的闭源系统(如Wan2.7)仍有差距
- 基础模型的选择(MLLM planner和DiT renderer)对最终效果有较大制约
总体来看,Bernini 的思想是:不要强行让一个模型同时完成理解、规划和渲染,而是把步骤拆开使用各自擅长的模型进行处理,再用一个合适的视觉语义空间把它们接起来。对于视频生成和视频编辑来说,这可能比单纯扩大模型规模更有启发。