这篇笔记整理了两篇相关论文:
- 综述:Multi-Agent Collaboration Mechanisms: A Survey of LLMs(Tran et al., 2025)——系统梳理 LLM-based 多智能体系统的协作类型、结构、策略和协调机制
- 框架:Multi-Agent Collaboration: Harnessing the Power of Intelligent LLM Agents(Talebirad & Nadiri, 2023)——提出一套具体的多智能体系统构建方案,并分析 Auto-GPT、BabyAGI 等系统
一、综述框架(Tran et al., 2025)
单个 LLM 的上限很明显:幻觉、慢思考、知识边界。多智能体系统(MAS)的思路是分工协作:把复杂任务分解,让多个 agent 各司其职,通过协作达成单个模型难以完成的目标。
这篇综述的核心贡献是提出了一套统一的分析框架,用 collaboration channel 为分析单元,从类型、结构、策略三个维度刻画 LLM-based MAS 的协作机制。
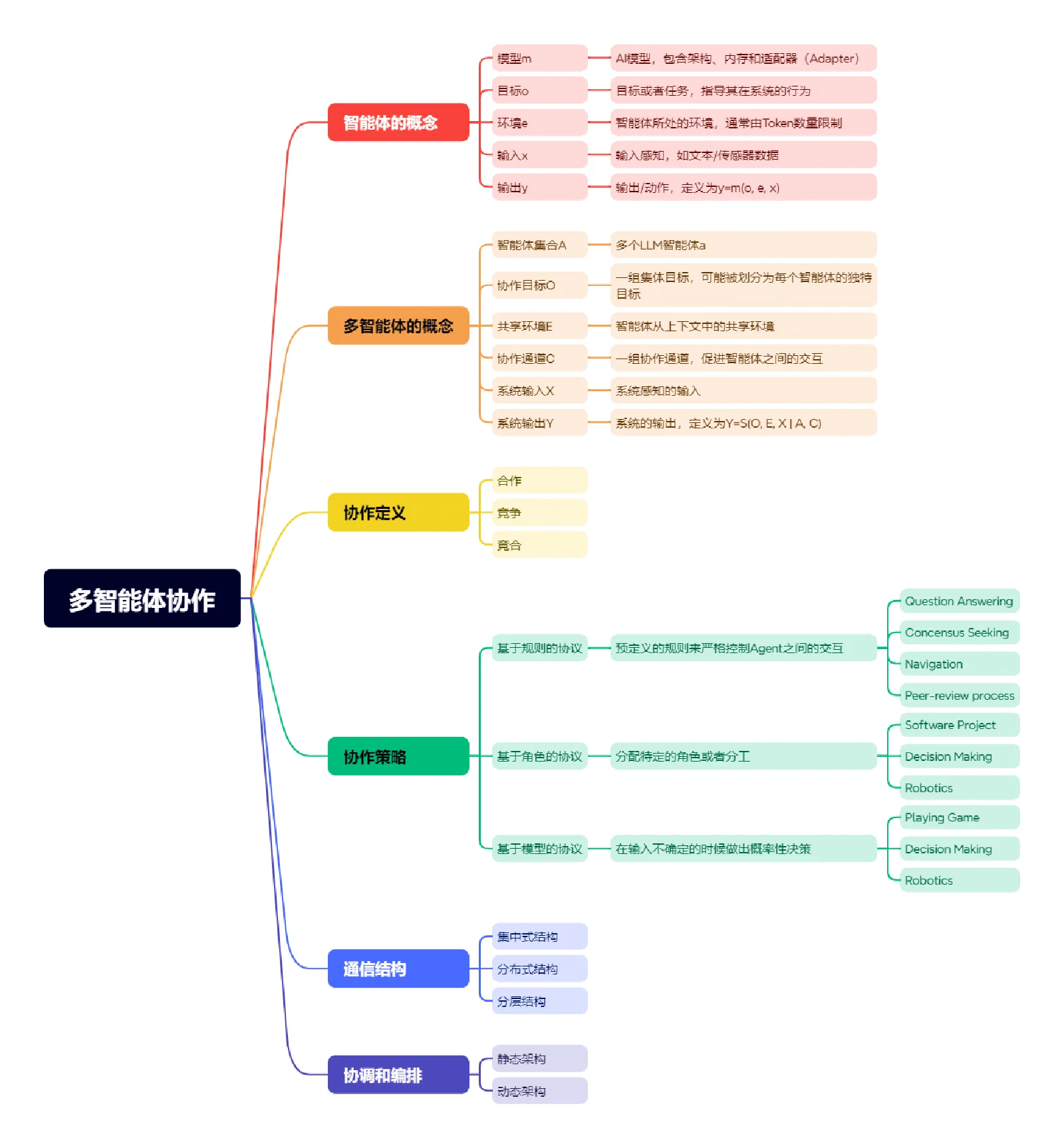
1.1 协作类型
| 类型 | 定义 | 优点 | 缺点 | 典型场景 |
|---|---|---|---|---|
| Cooperation | agent 共享同一目标,分工协作 | 任务分配清晰,设计简单 | 目标偏差会放大错误,单点失败影响全局 | 代码生成、问答、决策 |
| Competition | agent 各自优化自身目标,可能相互对立 | 促进更优解,提升系统鲁棒性 | 需要冲突解决机制,过度竞争会影响对齐 | 辩论、游戏对抗、候选答案筛选 |
| Coopetition | 在共享任务上合作,在部分目标上竞争 | 平衡各方利益,更接近现实决策场景 | 研究还少,机制复杂 | 谈判、MoE 模型 |
Cooperation 是目前最主流的形式。CAMEL 用角色扮演对话让两个 agent 协作完成任务;AutoGen 允许灵活定义 agent 行为和通信模式;MetaGPT 把 SOPs 编码进提示,让 agent 像流水线一样分工。
Competition 最典型的用途是辩论——多个 agent 持不同立场互相质疑,最后由裁判 agent 综合。LLMARENA 在 7 个游戏环境里系统评测了竞争式 MAS。
Coopetition 尚处于早期。MoE(Mixture of Experts)在某种程度上符合这个模式:多个专家模型竞争上岗,但最终结果是合作产出。
1.2 协作策略
| 策略 | 定义 | 优点 | 缺点 | 典型场景 |
|---|---|---|---|---|
| Rule-based | agent 交互严格受预定义规则约束 | 高效、可预测、一致性好 | 适应性差,规则集随任务复杂度指数增长 | 问答、共识搜索、导航、同行评审 |
| Role-based | 每个 agent 承担特定角色和职责 | 模块化、可复用,发挥各自专长 | 角色僵化时难以应对预期外场景 | 软件开发、机器人协作 |
| Model-based | agent 基于对环境和他人的概率模型做决策 | 适应动态环境,对不确定性鲁棒 | 实现复杂,计算开销大 | 游戏、机器人、动态决策 |
Rule-based 的典型是同行评审场景——论文评审流程本身就是一套规则,agent 按步骤执行。Role-based 的典型是 ChatDev 和 MetaGPT,把软件开发团队的角色(PM、架构师、开发者、测试员)映射给不同 agent。Model-based 则常见于博弈和机器人场景,agent 需要推断对手意图并动态调整策略。
1.3 通信结构
| 结构 | 定义 | 优点 | 缺点 | 典型场景 |
|---|---|---|---|---|
| Centralized | 所有协作决策由中央 agent 统筹 | 简单,资源分配高效 | 中央节点是单点故障,系统韧性差 | 决策制定 |
| Decentralized | 决策分散在多个 agent,点对点通信 | 单点失败不影响全局,可扩展性高 | 通信开销大,资源分配效率低 | 问答、推理、代码生成 |
| Hierarchical | agent 分层排列,跨层级通信受限 | 任务在层级间分配,降低单点压力 | 底层故障向上传播,延迟高 | 代码生成、问答、故事生成 |
Centralized 的典型是 Federated Learning(FL)——中央聚合节点协调所有客户端 agent。Decentralized 的典型是 MARG(多 agent 论文评审)。Hierarchical 的典型是 DyLAN,用多层 agent 网络动态筛选最优贡献者。
1.4 协调与编排
协调决定协作信道如何被创建、排序和管理,分两类:
- 静态编排:依赖预先定义的领域知识和规则建立协作信道。典型是顺序链式调用(sequential chaining)——前一个 agent 的输出是后一个的输入。优点是一致性好,缺点是遇到预定义规则外的情况会失效
- 动态编排:系统实时分配角色和信道,适应变化的任务需求。典型是 Management Agent 根据任务动态构建 DAG(有向无环图),或 Solo Performance Prompting(SPP)在运行时动态生成对应的 persona
二、框架实现(Talebirad & Nadiri, 2023)
如果综述回答的是"多智能体系统有哪些协作方式",这篇回答的是"一个具体的多智能体系统怎么设计和实现"。
2.1 Agent 的形式化表示
系统被建模为图 $G(V, E)$,$V$ 是 agent 和插件的集合,$E$ 是连接通道。
每个 agent $i$ 表示为五元组 $A_i = (L_i, R_i, S_i, C_i, H_i)$:
- $L_i$(语言模型):具体模型实例及配置(temperature 等)。GPT-4 适合深度推理,GPT-3.5-turbo 适合快速响应
- $R_i$(角色):agent 在系统中的职责
- $S_i$(状态):当前知识库和"想法"——知识是对环境的理解,想法是当前关注点,每次交互后更新
- $C_i$(创建权限):是否有权动态创建新 agent
- $H_i$(停止权限):有权叫停哪些 agent
每个插件 $j$ 表示为 $P_j = (F_j, C_j, U_j)$:功能集合、配置参数、使用约束。插件让 agent 能访问外部工具、数据库、API。
2.2 关键机制
动态 agent 创建:当 $C_i = \text{true}$ 时,agent 可以在运行时动态生成新 agent,为其分配角色和权限。这让系统在负载突然增加时自动扩容,而不需要提前规划所有 agent。
反馈机制:
- Inter-agent 反馈:agent 之间互相提供改进意见,参考 CAMEL 的 Inception Prompting
- 自反馈:用一对 agent 模拟——一个给反馈,一个修改输出,免去人工介入
Oracle Agent:无状态、无记忆,每次完全基于当前输入行动。适合做独立评估——不受历史偏见影响,常用于监控主 agent 的响应质量。
Supervisor Agent:持续监控主 agent 的任务进度,检测到死循环或偏离时主动发起停止命令。把"需要人类一直盯着"的监督工作自动化。
2.3 案例:Auto-GPT 与 BabyAGI
论文用这套框架重新建模了两个知名系统:
- Auto-GPT:建模为单 agent,浏览器/文件/代码执行等能力对应不同插件;Supervisor Agent 检测死循环;Oracle Agent 做安全监控
- BabyAGI:建模为三 agent 系统——任务创建 agent、优先级排序 agent、执行 agent;向量数据库作为插件负责任务存储和检索
2.4 案例:法庭与软件开发
两个场景展示框架的通用性:
法庭模拟:法官、陪审团、控辩律师、证人、书记员各对应一个 agent,每个配备对应工具插件(法律知识库、证据分析工具、文档管理等),按真实庭审流程交互。
软件开发:UX 设计师、产品经理、架构师、开发者、测试员、UI 设计师、调试员各为一个 agent,Oracle Agent 做整体质量反馈。映射了真实软件团队的分工结构。
三、应用领域
以下是两篇论文覆盖的主要实际系统,按领域整理:
物联网 / 语义通信
| 方法 | 主要贡献 | 缺点 |
|---|---|---|
| LLM-SC | LLM 作为知识生成器增强语义解码器 | 计算资源需求高 |
| LaMoSC | LLM 驱动多模态融合语义通信,低信噪比下稳健 | 计算资源需求高 |
| LAM-MSC | 联合编码器处理多模态数据 | 计算资源需求高 |
| GMAC | LLM 实现状态与语言的语义对齐,支持无通信协作 | 计算资源需求高 |
物联网方向的共同瓶颈:LLM 的计算开销在边缘设备上难以承受,这是结构性矛盾。
自然语言生成
| 方法 | 主要贡献 | 缺点 |
|---|---|---|
| LLM-Blender | 多 LLM 集成候选排序 | O(n) 次推理,开销大 |
| SOT | 并行生成答案框架再填充 | 评估质量受限 |
| Meta-Prompting | 元提示切换专家角色 | 需要大上下文窗口 |
| MAD | 两 agent 辩论 + 评判者监控 | 长场景难保连贯 |
| ChatDev | 聊天链拆解软件开发为子任务 | 需求不清晰时难理解任务 |
| AgentVerse | 招募→决策→执行→评估四阶段 | agent 间通信存在挑战 |
| OpenAI Swarm | 例程与交接机制的轻量级编排框架 | 尚未生产就绪 |
社会与文化
| 方法 | 主要贡献 | 缺点 |
|---|---|---|
| TE | 模拟人类参与者样本,揭示一致偏差 | 需要更多人类行为数据 |
| AgentInstruct | 跨 agent 迭代细化生成多样化数据 | 需要人工构建生成流程 |
| CulturePark | 促进跨文化交流模拟,生成多文化训练数据 | 低资源文化效果有限 |
| SocialMind | AR 眼镜实时整合多模态社交线索 | 依赖先进边缘硬件 |
四、几点观察
协作类型的研究严重不均衡。 Cooperation 有大量工作,Competition 有一些,Coopetition 几乎空白。但现实任务往往是混合的——谈判、政策制定这类场景天然就是合作竞争,这个方向的研究潜力还没被充分挖掘。
Supervisor Agent 是最实用的设计。 Auto-GPT 卡死循环是众所周知的问题,用一个独立 agent 监控主流程、发现异常就干预,比靠 prompt engineering 防止循环更可靠,也比人工盯着省力。这个机制简单但实用,在工程落地上价值很高。
评估指标是整个方向的核心瓶颈。 论文里提到,传统的任务评估指标很难衡量多 agent 系统整体的表现——输出是多个 agent 协作的结果,归因本身就很难。单个任务的准确率能测,但"协作质量"怎么测、“分工是否合理"怎么量化,目前没有标准答案。
LLM 本身不是为协作训练的。 综述最后指出一个根本性问题:现有 LLM 是作为独立模型训练的,多 agent 协作是推理时的"外挂”,而不是训练目标。这意味着 agent 之间的协调行为(谈判、妥协、信任建立)依赖 prompt 工程而非模型能力本身,天花板比较明显。