MCTS
MC-DML
[2504.16855] Monte Carlo Planning with Large Language Model for Text-Based Game Agents
主要解决的问题
解决了文字冒险游戏中 AI 规划效率低、缺乏语言理解与经验记忆能力。
面临挑战
- 游戏环境很复杂
- 传统的MCTS有局限性
- LLM难以将规划转化成可执行动作,且无法平衡探索与利用
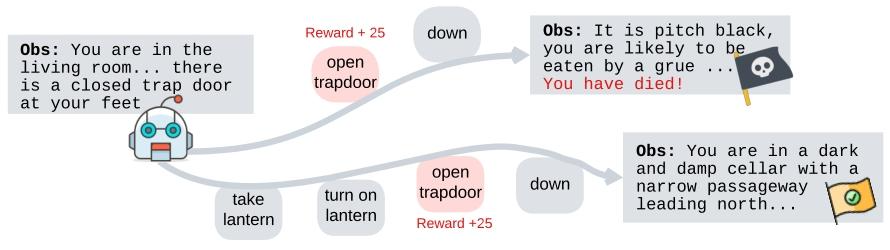
核心方法
MC-DML(Monte Carlo planning with Dynamic Memory-guided Large language model)
- 四阶段规划流程:沿用 MCTS 的Selection, Expansion, Simulation, Backpropagation四阶段。在扩展阶段引入 LLM 作为先验策略,让 LLM 基于场景文本为可选动作分配非均匀搜索优先级;模拟阶段通过多轮推演评估动作结果,回溯阶段更新节点价值与访问次数。
- 双动态记忆机制:
- 「 trial 内记忆($M_i$)」:存储当前轨迹历史(如 “前一观测 - 动作 - 当前观测”),帮 LLM 结合当下语境生成动作概率分布;
- 「 trial 间记忆($M_c$)」:存储过去失败轨迹的反思(如 “无光源时勿入黑暗区域”),动态调整动作价值评估,避免重复犯错。
- 动作选择公式优化:在 PUCT(改进型 MCTS)公式基础上,将 LLM 生成的动作概率(结合双记忆)融入计算,确保选择既符合语言逻辑又兼顾探索-利用平衡。